搜索到
27
篇与
的结果
-
 journalctl——systemd日志查询工具详解 journalctl是systemd日志系统的查询工具。当你某个服务启动失败或出现错误时,系统会提示你使用这个工具来排查。使用grep、awk这类工具对日志进行处理时,可能遇到下面的情况导致排查困难。日志文件太大,grep半天没反应想看某个时间段的日志,结果要写一堆复杂的正则表达式系统重启后,之前的日志找不到了想看某个服务的完整日志链路,结果要翻好几个不同的文件基础用法直接使用journalctl命令,会看到系统从启动开始的所有日志。不过这样看起来会很乱,而且信息量巨大。加个-f参数,就像tail -f一样,可以实时显示最新的日志。当怀疑某个服务有问题的时候,开着这个命令,然后去操作一下,立马就能看到相关的日志输出。按时间查看日志#查看今天的日志 journalctl --since today #或者看昨天的: journalctl --since yesterday #看某个时间段的 journalctl --since "2024-01-15 14:00:00" --until "2024-01-15 15:00:00"按服务查看日志#只看nginx服务的日志 journalctl -u nginx #实时监控某个服务: journalctl -u nginx -f #有时候一个服务重启了好几次,你想看它的历史记录: journalctl -u nginx --since "1 hour ago"进阶技巧按优先级过滤#只显示错误级别的日志 journalctl -p err查看内核日志journalctl -k该命令等同于dmesg,但是journalctl的输出格式更友好,而且可以结合其他参数使用。按进程ID查看 有时候你知道某个进程有问题,可以直接按PID查看:journalctl _PID=1234查看启动信息 想看系统启动过程中发生了什么:journalctl -b如果系统重启过多次,你想看上一次启动的日志:journalctl -b -1这个功能在排查系统启动异常时特别有用。高级功能JSON格式输出 有时候你需要程序化处理日志,可以用JSON格式:journalctl -u nginx -o json这样输出的每一行都是一个JSON对象,方便后续处理。查看磁盘使用情况 journal日志会占用磁盘空间,你可以查看当前使用情况:journalctl --disk-usage如果空间不够,可以清理旧日志:journalctl --vacuum-time=7d只保留最近7天的日志。导出日志 有时候需要把日志发给其他人分析:journalctl -u myapp --since today > app_logs.txt反向查看日志 从最新的日志开始看:journalctl -r这个在查看最近发生的问题时很有用。配置优化持久化存储 默认情况下,有些系统的journal日志是存储在内存中的,重启后就丢失了。要启用持久化存储:sudo mkdir -p /var/log/journal sudo systemd-tmpfiles --create --prefix /var/log/journal sudo systemctl restart systemd-journald限制日志大小 编辑/etc/systemd/journald.conf:SystemMaxUse=1G SystemMaxFileSize=100M这样可以避免日志占用太多磁盘空间。常见问题和解决方案日志查看权限问题 有时候普通用户看不到某些日志,需要加入systemd-journal组:sudo usermod -a -G systemd-journal username日志时间显示问题 如果时间显示不对,可能是时区设置问题:journalctl --utc使用UTC时间显示。性能问题 如果journalctl查询很慢,可能是因为日志文件太大。可以考虑:清理旧日志调整日志级别使用更精确的过滤条件一些小技巧# 查看最近的错误日志,按时间倒序 journalctl -p err -r --since "1 hour ago" # 查看某个用户的所有日志 journalctl _UID=1000 # 查看系统启动耗时 systemd-analyze blame
journalctl——systemd日志查询工具详解 journalctl是systemd日志系统的查询工具。当你某个服务启动失败或出现错误时,系统会提示你使用这个工具来排查。使用grep、awk这类工具对日志进行处理时,可能遇到下面的情况导致排查困难。日志文件太大,grep半天没反应想看某个时间段的日志,结果要写一堆复杂的正则表达式系统重启后,之前的日志找不到了想看某个服务的完整日志链路,结果要翻好几个不同的文件基础用法直接使用journalctl命令,会看到系统从启动开始的所有日志。不过这样看起来会很乱,而且信息量巨大。加个-f参数,就像tail -f一样,可以实时显示最新的日志。当怀疑某个服务有问题的时候,开着这个命令,然后去操作一下,立马就能看到相关的日志输出。按时间查看日志#查看今天的日志 journalctl --since today #或者看昨天的: journalctl --since yesterday #看某个时间段的 journalctl --since "2024-01-15 14:00:00" --until "2024-01-15 15:00:00"按服务查看日志#只看nginx服务的日志 journalctl -u nginx #实时监控某个服务: journalctl -u nginx -f #有时候一个服务重启了好几次,你想看它的历史记录: journalctl -u nginx --since "1 hour ago"进阶技巧按优先级过滤#只显示错误级别的日志 journalctl -p err查看内核日志journalctl -k该命令等同于dmesg,但是journalctl的输出格式更友好,而且可以结合其他参数使用。按进程ID查看 有时候你知道某个进程有问题,可以直接按PID查看:journalctl _PID=1234查看启动信息 想看系统启动过程中发生了什么:journalctl -b如果系统重启过多次,你想看上一次启动的日志:journalctl -b -1这个功能在排查系统启动异常时特别有用。高级功能JSON格式输出 有时候你需要程序化处理日志,可以用JSON格式:journalctl -u nginx -o json这样输出的每一行都是一个JSON对象,方便后续处理。查看磁盘使用情况 journal日志会占用磁盘空间,你可以查看当前使用情况:journalctl --disk-usage如果空间不够,可以清理旧日志:journalctl --vacuum-time=7d只保留最近7天的日志。导出日志 有时候需要把日志发给其他人分析:journalctl -u myapp --since today > app_logs.txt反向查看日志 从最新的日志开始看:journalctl -r这个在查看最近发生的问题时很有用。配置优化持久化存储 默认情况下,有些系统的journal日志是存储在内存中的,重启后就丢失了。要启用持久化存储:sudo mkdir -p /var/log/journal sudo systemd-tmpfiles --create --prefix /var/log/journal sudo systemctl restart systemd-journald限制日志大小 编辑/etc/systemd/journald.conf:SystemMaxUse=1G SystemMaxFileSize=100M这样可以避免日志占用太多磁盘空间。常见问题和解决方案日志查看权限问题 有时候普通用户看不到某些日志,需要加入systemd-journal组:sudo usermod -a -G systemd-journal username日志时间显示问题 如果时间显示不对,可能是时区设置问题:journalctl --utc使用UTC时间显示。性能问题 如果journalctl查询很慢,可能是因为日志文件太大。可以考虑:清理旧日志调整日志级别使用更精确的过滤条件一些小技巧# 查看最近的错误日志,按时间倒序 journalctl -p err -r --since "1 hour ago" # 查看某个用户的所有日志 journalctl _UID=1000 # 查看系统启动耗时 systemd-analyze blame -
curl与wget详解 curl简介全称是"Client URL",顾名思义就是一个URL客户端工具。它最大的特点就是支持的协议特别多,HTTP、HTTPS、FTP、FTPS、SCP、SFTP、LDAP等等,基本上你能想到的网络协议它都支持。curl测试API接口非常方便。比如说要测试一个REST API,用curl简直不要太方便:[root@webtest ~]# curl -X GET https://v2.jinrishici.com/token {"status":"success","data":"5w1dZp7lNh+NpR0Ws6OG6TGCqp/2UgMf"}这样就能快速看到接口返回的数据,比打开浏览器或者用Postman要快多了。curl还有个很牛的地方就是它的参数特别丰富,几乎可以模拟任何HTTP请求。想要发送POST请求?没问题:curl -X POST -H "Content-Type: application/json" -d '{"name":"张三","age":25}' https://api.example.com/users需要带认证信息?也很简单:curl -u username:password https://api.example.com/protected 或者用Bearer token: curl -H "Authorization: Bearer your_token_here" https://api.example.com/datawgetwget简介wgetwget的全称是"Web Get",它主要是用来从网络上获取文件的。相比curl,wget更专注于下载这一件事,在下载方面它做得确实很出色。wget有个递归下载功能。有一次需要备份一个静态网站,用wget一条命令就搞定了:wget -r -np -k -L -p https://example.com/这条命令会把整个网站都下载下来,包括CSS、JS、图片等所有资源,而且还会自动调整链接,下载完直接就能在本地打开。wget还有个很实用的功能就是断点续传。下载大文件的时候网络断了不用担心,加个-c参数就能接着下载:wget -c https://example.com/bigfile.zip 这个功能在网络不稳定的时候简直是救命稻草。两者的主要区别在哪里?最大的区别就是设计理念不同。curl更像是一个瑞士军刀,什么都能干,但是每样都不是最专业的;wget就像是一个专业的下载工具,在下载这件事上做得特别精细。从使用场景来说,一般是这样选择的:需要测试API、发送复杂HTTP请求的时候用curl单纯下载文件,特别是大文件或者需要递归下载的时候用wget需要在脚本里处理HTTP响应数据的时候用curl需要镜像整个网站或者批量下载的时候用wgetcurl的高级用法说到curl的高级用法,那可真是太多了。我经常用到的几个技巧分享给大家:保存响应头信息有时候需要查看服务器返回的头信息,可以用-I参数:curl -I https://www.baidu.com或者既要响应体又要响应头:curl -i https://api.example.com/data 跟随重定向默认情况下curl不会跟随重定向,需要加-L参数:curl -L https://short.url/abc123 设置超时时间网络不好的时候设置个超时时间很有必要:curl --connect-timeout 10 --max-time 30 https://slow.server.com使用代理需要通过代理访问的时候:curl --proxy http://proxy.server:8080 https://example.com 上传文件curl还能上传文件,这个功能很多人不知道:curl -X POST -F "file=@/path/to/file.txt" https://upload.example.com保存和使用Cookie处理需要登录的网站时,Cookie管理很重要:#保存cookie curl -c cookies.txt -d "username=admin&password=123456" https://example.com/login # 使用cookie curl -b cookies.txt https://example.com/protectedwget的实用技巧wget虽然看起来简单,但是用好了也很强大。限制下载速度在服务器上下载大文件的时候,为了不影响其他服务,可以限制下载速度:wget --limit-rate=200k https://example.com/bigfile.zip后台下载下载大文件时可以放到后台运行:wget -b https://example.com/hugefile.iso下载进度会保存在wget-log文件里,可以用tail命令查看: tail -f wget-log批量下载有个URL列表文件的话,可以批量下载:wget -i urls.txturls.txt文件里每行一个URL就行。设置重试次数网络不稳定的时候可以设置重试:wget --tries=3 --waitretry=2 https://unstable.server.com/file.zip递归下载的高级选项递归下载网站的时候,有很多参数可以控制行为:wget -r -np -nd -A "*.pdf" -R "*.html" https://example.com/documents/这条命令会递归下载所有PDF文件,但是排除HTML文件,而且不创建目录结构。实际工作中的应用场景监控网站可用性写个简单的脚本监控网站是否正常:#!/bin/bash response=$(curl -s -o /dev/null -w "%{http_code}" https://mywebsite.com) if [ $response -eq 200 ]; then echo "网站正常" else echo "网站异常,状态码:$response" fi自动化部署脚本部署的时候经常需要下载最新的安装包:#!/bin/bash # 获取最新版本号 latest_version=$(curl -s https://api.github.com/repos/user/project/releases/latest | grep tag_name | cut -d '"' -f 4) # 下载最新版本 wget https://github.com/user/project/releases/download/${latest_version}/project-${latest_version}.tar.gz API接口测试 测试POST接口的时候,curl特别方便: # 测试用户注册接口 curl -X POST \ -H "Content-Type: application/json" \ -d '{ "username": "testuser", "email": "test@example.com", "password": "123456" }' \ https://api.example.com/register文件备份定期备份重要文件到远程服务器:#!/bin/bash # 打包文件 tar -czf backup-$(date +%Y%m%d).tar.gz /important/data/ # 上传到远程服务器 curl -T backup-$(date +%Y%m%d).tar.gz ftp://backup.server.com/backups/ --user username:password常见问题和解决方案用这两个工具的时候,经常会遇到一些问题,常见的几个:SSL证书问题有时候遇到自签名证书或者证书有问题的网站,可以跳过证书验证:# curl跳过证书验证 curl -k https://self-signed.example.com # wget跳过证书验证 wget --no-check-certificate https://self-signed.example.com/file.zip不过这样做有安全风险,生产环境要谨慎使用。中文文件名乱码下载中文文件名的文件时可能会乱码,可以设置编码:wget --restrict-file-names=nocontrol https://example.com/中文文件.zip大文件下载超时下载大文件时经常会超时,可以调整超时设置:# curl设置超时 curl --connect-timeout 30 --max-time 3600 -O https://example.com/bigfile.zip # wget设置超时 wget --timeout=30 --read-timeout=3600 https://example.com/bigfile.zip
-
服务器资源需求评估惯用方法 资源估算很关键,既关系到成本控制,也影响业务稳定性。CPU资源估算公式和方法CPU的估算相对来说比较复杂,因为不同类型的应用对CPU的需求差别很大。我总结了一套比较实用的计算方法。基础CPU需求计算公式CPU核心数 = (并发用户数 × 单用户CPU消耗 × 安全系数) / CPU利用率目标关键参数说明并发用户数:同时在线并产生请求的用户数单用户CPU消耗:每个用户请求平均消耗的CPU时间安全系数:通常取1.5-2.0CPU利用率目标:建议控制在70%以下不同应用类型的CPU需求参考表应用类型单用户CPU消耗(ms)推荐配置(1000并发)备注静态网站5-102-4核主要是文件读取简单Web应用20-504-8核基础CRUD操作复杂业务系统100-2008-16核复杂查询和计算实时计算200-50016-32核大量数据处理图像/视频处理500-100032核以上CPU密集型任务实际计算示例假设我们有一个电商网站:预期并发用户:2000人应用类型:复杂业务系统单用户CPU消耗:150ms安全系数:1.8CPU利用率目标:70%计算过程:CPU核心数 = (2000 × 0.15 × 1.8) / 0.7 = 771 / 0.7 ≈ 11核 建议配置:12-16核CPU内存需求精确计算内存的估算相对简单一些,但也有一套科学的计算方法。内存需求计算公式总内存需求 = 系统基础内存 + 应用内存 + 连接内存 + 缓存内存 + 预留内存各组件内存需求详细表格组件类型基础占用计算公式说明操作系统1-2GB固定值Linux系统基础占用Java应用512MB-2GB堆内存 + 非堆内存JVM参数配置Node.js应用100-500MB根据代码复杂度相对轻量Python应用50-200MB根据框架和库Django/Flask差异较大Go应用10-100MB编译型语言内存占用很小MySQL128MB起InnoDB缓冲池大小建议总内存的70%Redis根据数据量数据大小 × 1.2包含持久化开销Nginx2-10MB连接数 × 2KB反向代理占用连接内存计算公式连接内存 = 最大连接数 × 单连接内存占用不同服务的单连接内存占用:HTTP连接:2-8KB数据库连接:1-4MBWebSocket连接:4-16KB实际内存计算案例以电商网站为例:并发用户:2000人技术栈:Java + MySQL + Redis数据量:用户数据50万条,商品数据10万条组件计算过程内存需求操作系统固定2GBJava应用堆内存4GB + 非堆1GB5GBHTTP连接2000 × 8KB16MBMySQL数据量约2GB,缓冲池设置8GBRedis热点数据500MB × 1.2600MB预留空间总量的20%3GB总计 约19GB建议配置:24GB或32GB内存存储空间规划计算存储的估算看起来简单,实际上坑也不少。我整理了一套比较完整的计算方法。存储需求计算公式总存储需求 = 业务数据 + 日志文件 + 备份空间 + 系统文件 + 增长预留不同数据类型的存储需求表数据类型单条记录大小增长系数备注用户基础信息1-2KB1.5包含索引开销订单记录2-5KB2.0关联数据较多商品信息5-20KB1.8包含图片路径等日志记录200-500B1.2压缩后存储图片文件100KB-2MB1.0原始大小视频文件10MB-1GB1.0原始大小日志文件存储计算日志存储需求 = 日请求量 × 单条日志大小 × 保留天数日志类型单条大小保留期压缩比访问日志300-500B30天0.3应用日志200-800B7天0.4错误日志500-2KB90天0.5数据库日志100-300B7天0.3存储计算实例电商网站存储需求计算:数据类型数量单条大小小计增长系数最终需求用户数据50万1.5KB750MB1.51.1GB商品数据10万15KB1.5GB1.82.7GB订单数据100万3KB3GB2.06GB访问日志100万/天400B400MB/天30天12GB应用日志50万/天600B300MB/天7天2.1GB图片文件20万张500KB100GB1.0100GB备份空间业务数据×3 33GB系统文件固定 20GB 20GB总计 约177GB建议配置:250GB SSD + 500GB HDD的组合网络带宽需求计算网络带宽经常被忽视,但其实很重要。带宽需求计算公式所需带宽(Mbps) = 并发用户数 × 平均页面大小(MB) × 8 × 安全系数 / 页面加载时间(秒)不同业务场景的带宽需求表业务类型平均页面大小目标加载时间安全系数单用户带宽需求企业官网2-5MB3秒1.520-42Kbps电商平台3-8MB2秒2.048-128Kbps视频网站10-50MB5秒1.829-144Kbps直播平台持续流量实时2.52-8Mbps游戏平台小数据包<100ms3.0100-500Kbps带宽计算实例电商网站带宽需求:并发用户:2000人平均页面大小:5MB目标加载时间:2秒安全系数:2.0计算过程:所需带宽 = 2000 × 5 × 8 × 2.0 / 2 = 40,000 Mbps = 40 Gbps优化建议:使用CDN减少源站压力图片压缩和懒加载静态资源缓存优化后实际需求可能只需要200-500Mbps数据库资源专项计算数据库的资源需求和应用服务器不太一样,需要单独考虑。数据库CPU计算公式数据库CPU需求 = (QPS × 平均查询时间 × CPU使用率) / 1000不同数据库的资源需求对比表数据库类型CPU效率内存需求存储IO适用场景MySQL中等中等高通用OLTPPostgreSQL高中等中等复杂查询MongoDB中等高中等文档存储Redis高高低缓存/会话Elasticsearch低高高全文搜索数据库内存分配建议表组件MySQLPostgreSQLMongoDB缓冲池70-80%25%50%连接缓存5-10%10%10%查询缓存5-10%25%20%系统预留10-20%40%20%数据库性能基准测试表配置MySQL QPSPostgreSQL QPSMongoDB QPSRedis QPS2核4GB1,000-2,000800-1,5002,000-4,00050,000-80,0004核8GB3,000-5,0002,500-4,0006,000-10,000100,000-150,0008核16GB8,000-12,0006,000-10,00015,000-25,000200,000-300,00016核32GB15,000-25,00012,000-20,00030,000-50,000400,000-600,000注:QPS数据基于标准OLTP场景,实际性能会因查询复杂度而变化容器化环境资源计算现在容器化部署越来越流行,资源计算方式也有所不同。容器资源计算公式容器总资源 = Σ(单容器资源 × 副本数 × 资源超分比)Kubernetes资源配置参考表服务类型CPU RequestCPU LimitMemory RequestMemory Limit副本数建议Web前端100m500m128Mi512Mi3-5API服务200m1000m256Mi1Gi3-10数据库1000m2000m2Gi4Gi1-3缓存服务100m500m512Mi2Gi2-3消息队列200m800m512Mi2Gi2-3容器资源超分配比例表资源类型开发环境测试环境生产环境说明CPU4:12:11.5:1超分比例内存2:11.5:11.2:1相对保守存储3:12:11:1生产不超分ROI计算公式投资回报率 = (收益增长 - 成本增长) / 成本增长 × 100%示例:通过性能优化,响应时间从3秒降到1秒,转化率提升20%,月收入增加10万,而优化成本只有2万,那么ROI就是400%监控指标和告警阈值设置监控系统一定要做好,这是运维的眼睛。我总结了一套完整的监控指标体系。核心监控指标阈值表指标类型正常范围警告阈值严重阈值监控频率CPU使用率<60%70%85%1分钟内存使用率<70%80%90%1分钟磁盘使用率<70%80%90%5分钟磁盘IO等待<10%20%40%1分钟网络带宽<60%70%85%1分钟响应时间<500ms1s3s实时错误率<0.1%1%5%实时连接数<1000根据配置根据配置1分钟应用层监控指标表指标Java应用Node.js应用Python应用Go应用堆内存使用<80%N/A<80%<80%GC频率<10次/分钟N/A<5次/分钟<1次/分钟线程数<500N/A<200<1000连接池<80%<80%<80%<80%性能测试和容量规划光有理论计算还不够,性能测试是验证估算准确性的重要手段。性能测试场景设计表测试类型并发用户数持续时间目标指标测试目的基准测试10-5010分钟建立基线了解基础性能负载测试预期并发30分钟响应时间<1s验证正常负载压力测试1.5×预期15分钟系统不崩溃找到性能瓶颈峰值测试3×预期5分钟快速恢复验证突发处理稳定性测试0.8×预期24小时无内存泄漏长期稳定性性能测试工具对比表工具适用场景并发能力学习成本报告质量JMeter通用Web测试中等中等好wrk简单HTTP测试高低一般LoadRunner企业级测试很高高很好ArtilleryNode.js友好中等低好Gatling高性能测试很高中等很好实际案例:电商平台完整资源规划下面用一个完整的案例来演示整个资源估算过程。业务需求分析某电商平台预期指标:注册用户:100万日活用户:10万峰值并发:5000人商品数量:50万日订单量:1万单图片文件:100万张详细资源计算过程1. Web服务器资源计算CPU需求:并发用户:5000人单用户CPU消耗:100ms(复杂业务)安全系数:1.8CPU利用率目标:70%CPU核心数 = (5000 × 0.1 × 1.8) / 0.7 = 1286核 考虑到单机限制,建议配置:8台 × 16核 = 128核内存需求:组件计算需求系统基础8台 × 2GB16GBJava应用8台 × 8GB64GB连接内存5000 × 8KB40MB预留20%16GB总计 96GB2. 数据库服务器资源计算预估QPS:查询QPS:2000写入QPS:500总QPS:2500根据性能基准表,需要8核16GB配置,考虑到安全系数,建议配置:16核32GB3. 缓存服务器资源计算Redis内存需求:用户会话:10万 × 2KB = 200MB商品缓存:5万 × 10KB = 500MB查询缓存:预估1GB总计:1.7GB × 1.5 = 2.6GB建议配置:4核8GB4. 存储需求计算数据类型计算过程存储需求用户数据100万 × 2KB × 1.53GB商品数据50万 × 20KB × 1.818GB订单数据365万 × 5KB × 2.036GB图片文件100万 × 800KB800GB日志文件计算得出50GB备份空间业务数据 × 3171GB总计 1078GB5. 带宽需求计算使用CDN优化后:动态内容:5000用户 × 100KB × 8 / 2秒 = 2Gbps考虑安全系数:2Gbps × 1.5 = 3Gbps实际配置:500Mbps(CDN分担大部分流量)最终配置方案服务器类型配置数量月成本Web服务器16核32GB8台10.8万数据库服务器16核32GB SSD2台3.2万缓存服务器4核8GB2台0.8万负载均衡标准配置2台0.4万CDN服务500GB流量-0.5万总计 15.7万/月动态扩容策略静态配置往往无法应对业务的快速变化,动态扩容策略很重要。自动扩容触发条件表指标扩容阈值缩容阈值冷却时间扩容步长CPU使用率>70%<30%5分钟+1台内存使用率>80%<40%5分钟+1台响应时间>1秒<300ms3分钟+2台队列长度>100<102分钟+1台错误率>1%<0.1%10分钟+2台扩容成本效益分析扩容方式响应时间成本增加适用场景垂直扩容5-10分钟50-100%短期突发水平扩容2-5分钟20-50%持续增长预热扩容即时10-30%可预期峰值写在最后服务器资源估算确实是个技术活,需要综合考虑业务需求、技术架构、成本预算等多个因素。通过这些公式和表格,可以更科学地进行资源规划:核心要点回顾CPU估算:基于并发用户数和单用户消耗计算内存估算:分组件计算,预留20%安全空间存储估算:考虑数据增长和备份需求带宽估算:结合CDN优化,避免过度配置成本控制:对比不同方案,选择最优性价比实用建议基于实际业务需求估算,不要拍脑袋决定预留适当的扩容空间,但不要过度设计重视监控和性能测试,数据说话根据实际运行情况及时调整优化考虑动态扩容,应对业务变化最重要的是,要有持续优化的意识。系统上线只是开始,后续的监控、调优、扩容才是重头戏。技术在发展,业务在变化,资源配置也要跟着调整。没有完美的架构,只有合适的架构。资源估算也是一样,关键是要找到性能、成本、可靠性之间的平衡点。
-
free命令详解 执行free -h命令时,通常会看到这样的输出其中:total是总内存,这个最直观used包括了应用程序和缓存使用的内存free是完全空闲的内存,通常很小buff/cache是可以释放的缓存内存available是真正可用的内存,这个最重要shared是共享内存,通常不用太关注total:系统总内存total就是系统的总物理内存大小,比如8G内存条,这里显示的就是8G(会扣掉一些被内核占用的部分)。used:已使用内存used包括了:应用程序实际使用的内存内核使用的内存缓冲区和缓存使用的内存有时看到used很高,不代表应用程序真的用了那么多内存。很可能是Linux把大量内存用作了文件缓存。具体查看内存使用情况/proc/meminfo看详细分解cat /proc/meminfo | grep -E "(MemTotal|MemFree|MemAvailable|Buffers|Cached|SReclaimable)"Buffers就是缓冲区使用的内存Cached就是页面缓存使用的内存SReclaimable是可回收的内核数据结构把这几个加起来,基本就是free命令里buff/cache那一列的值。如果Cached特别大,说明系统缓存了很多文件;如果Buffers很大,可能是有大量的磁盘IO操作。ps命令查看进程内存使用# 按内存使用量排序显示进程 ps aux --sort=-%mem | head -10 # 或者用这个更直观的格式 ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem | head -10 # 某个应用的总内存使用,比如统计所有java进程的内存使用 ps aux | grep java | awk '{sum+=\$6} END {print "Total memory: " sum/1024 " MB"}'free:真正空闲的内存free显示的是完全没有被使用的内存。注意,这里不包括被用作缓冲区和缓存的内存,因为这些内存在需要的时候是可以立即释放给应用程序使用的。如果经常看到free的值很小,这是正常现象。Linux的设计哲学就是"空闲的内存是浪费的内存",系统会尽可能地把空闲内存用作文件缓存,提高系统性能。shared:共享内存shared显示的是被多个进程共享的内存大小。这部分内存主要包括:共享内存段(System V shared memory)tmpfs文件系统使用的内存一些其他的共享内存区域在日常运维中,一般特别关注这个数值。除非某个应用大量使用了共享内存,否则这个值通常不会很大。比如一些使用Redis的系统,如果Redis配置了大量的共享内存,这个值会比较高。但大多数情况下,这个数字都不是重点关注对象。buff/cache:缓冲区和缓存这个是Linux内存管理的精髓所在。buff/cache包括:缓冲区(buffers):用于缓存磁盘块设备的数据页面缓存(page cache):用于缓存文件内容Linux会把空闲内存用作文件缓存,这样当程序再次读取相同文件时,就可以直接从内存中获取,而不需要再次访问磁盘。这大大提高了系统的IO性能。关键是,这部分内存在应用程序需要时可以立即释放。所以虽然它们被标记为"已使用",但实际上是可用的。buff/cache的调整和优化手动清理缓存(谨慎使用)注意:生产环境别随便清理,会影响性能。# 清理页面缓存 echo 1 > /proc/sys/vm/drop_caches # 清理所有缓存 sync && echo 3 > /proc/sys/vm/drop_caches调整缓存策略控制swap使用倾向# 查看当前值 cat /proc/sys/vm/swappiness # 调整为10(让系统优先回收缓存而不是使用swap) echo "vm.swappiness = 10" >> /etc/sysctl.conf控制缓存回收压力# 调整目录和inode缓存回收 echo "vm.vfs_cache_pressure = 50" >> /etc/sysctl.conf不同场景的优化建议数据库服务器vm.swappiness = 1 vm.vfs_cache_pressure = 150文件服务器vm.swappiness = 10 vm.vfs_cache_pressure = 50调整完要用sysctl -p生效,然后观察系统表现。大多数情况下默认设置就够用了,没事别瞎调。available:真正可用的内存这个是最重要的指标!available显示的是应用程序可以使用的内存总量,包括:free的内存可以立即释放的buff/cache内存一些其他可回收的内存简单来说,available = free + 可回收的buff/cache这个数值才是真正需要关注的。只有当available很低的时候,才说明系统内存真的不够用了。判断系统内存是否充足,主要就看这个available值。只要它保持在一个合理的水平,就不用担心内存问题。
-
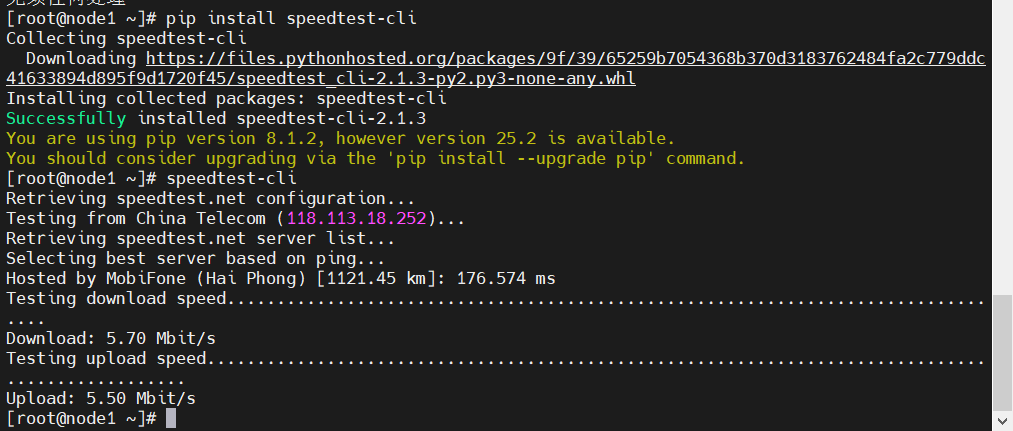
linux中常用带宽测量工具 公网测试工具:speedtest-cli安装# CentOS/RHEL系列 yum install epel-release yum install python-pip pip install speedtest-cli # Ubuntu/Debian系列 apt update # 安装 pipx sudo apt install pipx pipx ensurepath # 安装应用 pipx install speedtest-cli运行speedtest-cli使用该命令会自动选择服务器进行测速。不过有时候自动选择的服务器不太理想,你可以手动指定。先看看附近有哪些服务器:speedtest-cli --list | grep -i China [root@node1 ~]# speedtest-cli --list | grep -i China 71313) 中国电信 (Xuzhou, China) [1301.96 km] 16204) JSQY - Suzhou (Suzhou, China) [1576.10 km] 选一个延迟比较低的:speedtest-cli --server 71313iperf3:内网测试工具speedtest-cli虽然方便,但有个问题就是测试的是到公网的速度。如果想测试内网带宽,或者两台服务器之间的带宽,那就得用iperf3了。安装iperf3# CentOS/RHEL yum install iperf3 # Ubuntu/Debian apt install iperf3测试iperf3需要一台服务器做服务端,一台做客户端。在服务端运行:iperf3 -s在客户端运行: iperf3 -c 192.168.99.100客户端结果服务端结果默认测试10秒钟,也可以指定时间:iperf3 -c 服务端IP -t 30测试UDP带宽:iperf3 -c 192.168.99.100 -u -t 15客户端结果服务端结果仔细观察上面的测试结果可以看到,测试udp的速度时网速反而比tcp的要慢很多,而正常情况是udp速度要比tcp的块。出现这种状况的原因是iperf3 中 UDP 默认带宽只有1Mbps,而TCP会自动尝试使用所有可用带宽。解决这一现象的方案是测UDP时手动设置UDP带宽。iperf3 -u -b 1G -l 1400 -c 192.168.99.100客户端服务端wget/curl - 简单实用的下载测试如果想快速测一下下载速度,不想装额外的工具,那wget和curl就够用了。下载一个100MB的文件到/dev/null(相当于丢弃),然后显示下载速度。 wget :wget -O /dev/null http://speedtest.tele2.net/100MB.zipcurlcurl -o /dev/null http://speedtest.tele2.net/100MB.zip #查看更详细的信息 curl -o /dev/null -w "下载速度: %{speed_download} bytes/sec\n总时间: %{time_total}s\n" http://speedtest.tele2.net/100MB.zip 这种方法的好处是可以测试到特定服务器的速度,比如CDN节点或者合作伙伴的服务器。nload - 实时监控网络流量安装nload# CentOS/RHEL yum install nload # Ubuntu/Debian apt install nload运行nload它会显示一个实时的图表,显示当前的上传和下载速度。如果你有多个网卡,可以用左右箭头键切换。iftop - 看看谁在占用带宽iftop比nload更进一步,它不仅能显示总的流量,还能显示每个连接的流量情况。安装CentOS/RHEL yum install iftop # Ubuntu/Debian apt install iftop运行(需要root权限)iftopiftop的界面有点像top命令,显示当前所有网络连接的流量情况。可以看到每个IP地址的上传下载速度,这对于排查网络问题特别有用。nethogs - 进程级别的网络监控安装# CentOS/RHEL yum install nethogs # Ubuntu/Debian apt install nethogs运行(需要root权限)nethogsnethogs会显示每个进程的网络使用情况,包括进程名、PID、用户等信息。这对于排查哪个应用程序占用带宽特别有用。实用的测试技巧选择合适的测试时间网络带宽测试最好在不同时间段多测几次,因为网络状况会随时间变化。我一般会在早上、中午、晚上各测一次,这样能得到比较全面的数据。注意测试方向很多人只测下载速度,忽略了上传速度。但对于服务器来说,上传速度同样重要,特别是如果你的服务器需要向用户推送大量数据的话。考虑并发连接单线程测试得到的带宽可能不能反映真实情况。可以试试多线程测试:iperf3 -c 服务端IP -P 4这个命令会启动4个并行连接进行测试。记录测试结果把测试结果记录下来,建立一个基线。这样以后出现问题的时候,你就能快速判断是不是网络带宽的问题了。如果测试结果不理想,可以按这个顺序排查:先确认是不是测试方法的问题,换个工具再测一次检查服务器的网卡配置,看看是不是限速了联系网络管理员或者运营商,确认线路状况检查防火墙和安全组设置,看看是不是有限制