搜索到
27
篇与
的结果
-
 PHP-FPM进程假死问题处理思路 进程假死其实就是进程还在,但是不干活了。用ps命令看,进程确实存在,但就是不处理请求。PHP-FPM作为FastCGI进程管理器,负责管理PHP进程池。当它出现假死时,表现就是:进程存在但不响应新请求CPU使用率可能很低或者异常高内存占用可能持续增长日志可能停止更新或者出现异常快速定位和解决进程假死问题,关键是要:建立完善的监控体系,及时发现问题熟练掌握各种排查工具的使用针对常见场景做好预防措施特别要重视磁盘IO问题,这个经常被忽略但影响很大保持冷静,按照既定流程逐步排查磁盘IO问题特别值得重视,因为它往往比较隐蔽,不像CPU或内存问题那么明显。很多时候系统看起来资源充足,但就是响应慢,这时候就要想到是不是磁盘IO的问题了。快速判断是否为进程假死看进程状态ps aux | grep php-fpm正常情况下的输出如下:如果看到进程状态是D(不可中断睡眠)或者Z(僵尸进程),那基本就是有问题了。STAT: 进程状态码S: 睡眠状态s: 会话领导者l: 多线程+: 前台进程组R: 运行中D 状态的进程通常是在等待 I/O 操作完成,如磁盘读写Z 状态 (僵尸进程),僵尸进程是已经终止但父进程尚未调用 wait() 获取其退出状态的进程检查进程响应# 查看PHP-FPM状态页面(需要先配置) curl http://localhost/status # 或者直接测试PHP页面响应 curl -w "@curl-format.txt" -o /dev/null -s "http://your-site.com/test.php"如果curl一直卡住不返回,或者返回时间特别长,那就很可能是假死了。观察系统资源# 查看CPU使用情况 top -p `pgrep php-fpm | tr '\n' ',' | sed 's/,$//'` # 查看内存使用 free -h # 查看磁盘IO iostat -x 1深入分析假死原因strace可以实时查看进程在做什么系统调用:# 找到问题进程PID ps aux | grep php-fpm | grep -v master # 追踪系统调用 strace -p 进程PID -f -e trace=all查看进程调用栈如果strace信息太多看不过来,可以用gdb查看调用栈gdb -p 进程PID (gdb) bt (gdb) info threads (gdb) thread apply all bt分析PHP-FPM慢日志PHP-FPM有个很有用的功能就是慢日志,可以记录执行时间超过阈值的请求:在php-fpm.conf中配置 slowlog = /var/log/php-fpm/slow.log request_slowlog_timeout = 5s慢日志会记录详细的调用栈,比如: [26-Oct-2024 15:30:45] [pool www] pid 12345 script_filename = /var/www/html/index.php [0x00007f8b8c0c8000] curl_exec() /var/www/html/api.php:45 [0x00007f8b8c0c8100] api_call() /var/www/html/index.php:23 通过慢日志能很快定位到是哪个函数卡住了。常见的假死场景和解决方案数据库连接问题这个真的太常见了。数据库连接池满了,或者网络抖动,都可能导致PHP进程卡在数据库操作上。解决方案:设置合理的数据库连接超时时间使用连接池,避免频繁建立连接监控数据库连接数设置MySQL连接超时 $pdo = new PDO($dsn, $user, $pass, [ PDO::ATTR_TIMEOUT => 5, PDO::MYSQL_ATTR_INIT_COMMAND => "SET SESSION wait_timeout=30"外部API调用超时调用第三方API时没设置超时,对方服务挂了你也跟着挂。我见过太多这种情况了,一个支付接口的问题导致整个网站瘫痪。#使用curl时一定要设置超时 $ch = curl_init(); curl_setopt($ch, CURLOPT_TIMEOUT, 10); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 5);文件锁竞争多个进程同时操作同一个文件,可能导致死锁:#使用flock时要注意超时 $fp = fopen('data.txt', 'w'); if (flock($fp, LOCK_EX | LOCK_NB)) { // 获得锁,执行操作 fwrite($fp, $data); flock($fp, LOCK_UN); } else { // 获取锁失败,记录日志或者返回错误 error_log('Failed to acquire file lock'); } fclose($fp);磁盘IO问题导致的假死这个问题特别隐蔽,经常被忽略。磁盘IO性能差或者磁盘故障,会导致进程卡在文件读写操作上。#快速检测磁盘IO问题 # 查看磁盘IO使用率 iostat -x 1 5重点关注这几个指标:%util - 磁盘使用率,接近100%说明磁盘很忙await - 平均等待时间,超过20ms就要注意了svctm - 平均服务时间案例:服务器磁盘的%util一直在99%以上,但是通过top看CPU使用率很低。后来发现是磁盘坏道导致的,读写特别慢。找出占用IO的进程 # 安装iotop工具 apt install iotop -y # 实时查看IO使用情况 iotop -o -d 1 # 或者使用pidstat pidstat -d 1iotop的输出类似这样:Total DISK READ : 0.00 B/s | Total DISK WRITE : 12.34 M/s Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 15.67 M/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 1234 be/4 www 0.00 B/s 10.23 M/s 0.00 % 85.67 % php-fpm: pool www如果看到某个PHP-FPM进程的IO使用率特别高,那就要重点关注了。分析具体的文件操作# 使用lsof查看进程打开的文件 lsof -p 进程PID # 或者查看进程的文件描述符 ls -la /proc/进程PID/fd/案例:PHP程序在写日志时没有正确关闭文件句柄,导致同一个日志文件被打开了几千次,磁盘IO直接爆炸。磁盘空间不足的问题# 检查磁盘使用情况 df -h # 查找大文件 find /var/log -type f -size +100M -exec ls -lh {} \; # 查看目录大小 du -sh /var/log/*磁盘空间不足时,写操作会变得特别慢,甚至失败。PHP-FPM进程可能会卡在日志写入或者临时文件创建上。内存泄漏导致的假死PHP进程内存使用过多,触发系统的OOM机制,进程就卡住了。可以通过以下方式监控:# 查看进程内存使用 cat /proc/进程PID/status | grep VmRSS # 或者用ps ps -o pid,vsz,rss,comm -p 进程PID应急处理方案重启PHP-FPM服务# CentOS/RHEL systemctl restart php-fpm # Ubuntu/Debian systemctl restart php7.4-fpm # 或者直接kill掉重启 pkill php-fpm /usr/sbin/php-fpm -D不过重启会中断正在处理的请求,生产环境要慎重。平滑重启PHP-FPM支持平滑重启,不会中断现有连接:# 发送USR2信号进行平滑重启 kill -USR2 `cat /var/run/php-fpm.pid` # 或者使用systemctl systemctl reload php-fpm预防措施监控日志记录开启详细的日志记录,方便问题排查:php-fpm.conf log_level = notice access.log = /var/log/php-fpm/access.log access.format = "%R - %u %t \"%m %r\" %s %f %{mili}d %{kilo}M %C%%"定期重启一些老项目可能存在内存泄漏问题,可以设置定期重启# 添加到crontab,每天凌晨3点重启 0 3 * * * /usr/bin/systemctl reload php-fpm注意事项不要随便kill -9很多人遇到进程假死第一反应就是kill -9,但这样可能会导致数据不一致。最好先尝试kill -TERM让进程优雅退出。注意PHP-FPM版本差异不同版本的PHP-FPM配置参数可能不一样,升级时要注意兼容性。我就遇到过从PHP 7.2升级到7.4后,原来的配置不生效的情况。监控指标要合理设置监控阈值时不要太敏感,否则会产生很多误报。我之前设置响应时间超过1秒就告警,结果每天收到几十条告警消息,后来调整到5秒才比较合理。磁盘IO监控容易被忽略很多人只关注CPU和内存,忽略了磁盘IO。其实磁盘IO问题导致的服务假死非常常见,特别是那些有大量文件操作的应用。建议在监控系统中加入这些磁盘相关的指标:磁盘使用率(%util)平均等待时间(await)磁盘空间使用率inode使用率日志轮转PHP-FPM的日志文件会越来越大,一定要配置logrotate进行日志轮转,否则磁盘满了又是另一个问题。# /etc/logrotate.d/php-fpm /var/log/php-fpm/*.log { daily missingok rotate 7 compress delaycompress notifempty postrotate /bin/kill -USR1 `cat /var/run/php-fpm.pid 2>/dev/null` 2>/dev/null || true endscript }临时文件清理PHP会在/tmp目录下创建临时文件,如果程序异常退出,这些临时文件可能不会被清理。时间长了会占用大量磁盘空间和inode。# 定期清理PHP临时文件 find /tmp -name "php*" -type f -mtime +1 -delete # 清理session文件 find /var/lib/php/session -name "sess_*" -type f -mtime +1 -delete可以把这些命令加到crontab里定期执行。高级排查技巧使用perf分析性能对于复杂的性能问题,可以使用perf工具进行深入分析:# 安装perf工具 yum install perf -y # 对指定进程进行采样 perf record -p 进程PID -g -- sleep 30 # 查看报告 perf reportperf可以告诉你进程把时间都花在哪里了,对于定位性能瓶颈很有帮助。使用systemtap进行动态追踪systemtap是个更强大的工具,可以动态插入探针:# 监控文件IO操作 stap -e 'probe syscall.read, syscall.write { if (pid() == target()) printf("%s: %s\n", name, argstr) }' -x 进程PID不过systemtap比较复杂,一般情况下用strace就够了。分析core dump文件如果进程崩溃了,可以通过core dump文件分析崩溃原因:# 启用core dump ulimit -c unlimited echo '/tmp/core.%e.%p' > /proc/sys/kernel/core_pattern # 使用gdb分析core文件 gdb /usr/sbin/php-fpm /tmp/core.php-fpm.12345 (gdb) bt (gdb) info registers
PHP-FPM进程假死问题处理思路 进程假死其实就是进程还在,但是不干活了。用ps命令看,进程确实存在,但就是不处理请求。PHP-FPM作为FastCGI进程管理器,负责管理PHP进程池。当它出现假死时,表现就是:进程存在但不响应新请求CPU使用率可能很低或者异常高内存占用可能持续增长日志可能停止更新或者出现异常快速定位和解决进程假死问题,关键是要:建立完善的监控体系,及时发现问题熟练掌握各种排查工具的使用针对常见场景做好预防措施特别要重视磁盘IO问题,这个经常被忽略但影响很大保持冷静,按照既定流程逐步排查磁盘IO问题特别值得重视,因为它往往比较隐蔽,不像CPU或内存问题那么明显。很多时候系统看起来资源充足,但就是响应慢,这时候就要想到是不是磁盘IO的问题了。快速判断是否为进程假死看进程状态ps aux | grep php-fpm正常情况下的输出如下:如果看到进程状态是D(不可中断睡眠)或者Z(僵尸进程),那基本就是有问题了。STAT: 进程状态码S: 睡眠状态s: 会话领导者l: 多线程+: 前台进程组R: 运行中D 状态的进程通常是在等待 I/O 操作完成,如磁盘读写Z 状态 (僵尸进程),僵尸进程是已经终止但父进程尚未调用 wait() 获取其退出状态的进程检查进程响应# 查看PHP-FPM状态页面(需要先配置) curl http://localhost/status # 或者直接测试PHP页面响应 curl -w "@curl-format.txt" -o /dev/null -s "http://your-site.com/test.php"如果curl一直卡住不返回,或者返回时间特别长,那就很可能是假死了。观察系统资源# 查看CPU使用情况 top -p `pgrep php-fpm | tr '\n' ',' | sed 's/,$//'` # 查看内存使用 free -h # 查看磁盘IO iostat -x 1深入分析假死原因strace可以实时查看进程在做什么系统调用:# 找到问题进程PID ps aux | grep php-fpm | grep -v master # 追踪系统调用 strace -p 进程PID -f -e trace=all查看进程调用栈如果strace信息太多看不过来,可以用gdb查看调用栈gdb -p 进程PID (gdb) bt (gdb) info threads (gdb) thread apply all bt分析PHP-FPM慢日志PHP-FPM有个很有用的功能就是慢日志,可以记录执行时间超过阈值的请求:在php-fpm.conf中配置 slowlog = /var/log/php-fpm/slow.log request_slowlog_timeout = 5s慢日志会记录详细的调用栈,比如: [26-Oct-2024 15:30:45] [pool www] pid 12345 script_filename = /var/www/html/index.php [0x00007f8b8c0c8000] curl_exec() /var/www/html/api.php:45 [0x00007f8b8c0c8100] api_call() /var/www/html/index.php:23 通过慢日志能很快定位到是哪个函数卡住了。常见的假死场景和解决方案数据库连接问题这个真的太常见了。数据库连接池满了,或者网络抖动,都可能导致PHP进程卡在数据库操作上。解决方案:设置合理的数据库连接超时时间使用连接池,避免频繁建立连接监控数据库连接数设置MySQL连接超时 $pdo = new PDO($dsn, $user, $pass, [ PDO::ATTR_TIMEOUT => 5, PDO::MYSQL_ATTR_INIT_COMMAND => "SET SESSION wait_timeout=30"外部API调用超时调用第三方API时没设置超时,对方服务挂了你也跟着挂。我见过太多这种情况了,一个支付接口的问题导致整个网站瘫痪。#使用curl时一定要设置超时 $ch = curl_init(); curl_setopt($ch, CURLOPT_TIMEOUT, 10); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 5);文件锁竞争多个进程同时操作同一个文件,可能导致死锁:#使用flock时要注意超时 $fp = fopen('data.txt', 'w'); if (flock($fp, LOCK_EX | LOCK_NB)) { // 获得锁,执行操作 fwrite($fp, $data); flock($fp, LOCK_UN); } else { // 获取锁失败,记录日志或者返回错误 error_log('Failed to acquire file lock'); } fclose($fp);磁盘IO问题导致的假死这个问题特别隐蔽,经常被忽略。磁盘IO性能差或者磁盘故障,会导致进程卡在文件读写操作上。#快速检测磁盘IO问题 # 查看磁盘IO使用率 iostat -x 1 5重点关注这几个指标:%util - 磁盘使用率,接近100%说明磁盘很忙await - 平均等待时间,超过20ms就要注意了svctm - 平均服务时间案例:服务器磁盘的%util一直在99%以上,但是通过top看CPU使用率很低。后来发现是磁盘坏道导致的,读写特别慢。找出占用IO的进程 # 安装iotop工具 apt install iotop -y # 实时查看IO使用情况 iotop -o -d 1 # 或者使用pidstat pidstat -d 1iotop的输出类似这样:Total DISK READ : 0.00 B/s | Total DISK WRITE : 12.34 M/s Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 15.67 M/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 1234 be/4 www 0.00 B/s 10.23 M/s 0.00 % 85.67 % php-fpm: pool www如果看到某个PHP-FPM进程的IO使用率特别高,那就要重点关注了。分析具体的文件操作# 使用lsof查看进程打开的文件 lsof -p 进程PID # 或者查看进程的文件描述符 ls -la /proc/进程PID/fd/案例:PHP程序在写日志时没有正确关闭文件句柄,导致同一个日志文件被打开了几千次,磁盘IO直接爆炸。磁盘空间不足的问题# 检查磁盘使用情况 df -h # 查找大文件 find /var/log -type f -size +100M -exec ls -lh {} \; # 查看目录大小 du -sh /var/log/*磁盘空间不足时,写操作会变得特别慢,甚至失败。PHP-FPM进程可能会卡在日志写入或者临时文件创建上。内存泄漏导致的假死PHP进程内存使用过多,触发系统的OOM机制,进程就卡住了。可以通过以下方式监控:# 查看进程内存使用 cat /proc/进程PID/status | grep VmRSS # 或者用ps ps -o pid,vsz,rss,comm -p 进程PID应急处理方案重启PHP-FPM服务# CentOS/RHEL systemctl restart php-fpm # Ubuntu/Debian systemctl restart php7.4-fpm # 或者直接kill掉重启 pkill php-fpm /usr/sbin/php-fpm -D不过重启会中断正在处理的请求,生产环境要慎重。平滑重启PHP-FPM支持平滑重启,不会中断现有连接:# 发送USR2信号进行平滑重启 kill -USR2 `cat /var/run/php-fpm.pid` # 或者使用systemctl systemctl reload php-fpm预防措施监控日志记录开启详细的日志记录,方便问题排查:php-fpm.conf log_level = notice access.log = /var/log/php-fpm/access.log access.format = "%R - %u %t \"%m %r\" %s %f %{mili}d %{kilo}M %C%%"定期重启一些老项目可能存在内存泄漏问题,可以设置定期重启# 添加到crontab,每天凌晨3点重启 0 3 * * * /usr/bin/systemctl reload php-fpm注意事项不要随便kill -9很多人遇到进程假死第一反应就是kill -9,但这样可能会导致数据不一致。最好先尝试kill -TERM让进程优雅退出。注意PHP-FPM版本差异不同版本的PHP-FPM配置参数可能不一样,升级时要注意兼容性。我就遇到过从PHP 7.2升级到7.4后,原来的配置不生效的情况。监控指标要合理设置监控阈值时不要太敏感,否则会产生很多误报。我之前设置响应时间超过1秒就告警,结果每天收到几十条告警消息,后来调整到5秒才比较合理。磁盘IO监控容易被忽略很多人只关注CPU和内存,忽略了磁盘IO。其实磁盘IO问题导致的服务假死非常常见,特别是那些有大量文件操作的应用。建议在监控系统中加入这些磁盘相关的指标:磁盘使用率(%util)平均等待时间(await)磁盘空间使用率inode使用率日志轮转PHP-FPM的日志文件会越来越大,一定要配置logrotate进行日志轮转,否则磁盘满了又是另一个问题。# /etc/logrotate.d/php-fpm /var/log/php-fpm/*.log { daily missingok rotate 7 compress delaycompress notifempty postrotate /bin/kill -USR1 `cat /var/run/php-fpm.pid 2>/dev/null` 2>/dev/null || true endscript }临时文件清理PHP会在/tmp目录下创建临时文件,如果程序异常退出,这些临时文件可能不会被清理。时间长了会占用大量磁盘空间和inode。# 定期清理PHP临时文件 find /tmp -name "php*" -type f -mtime +1 -delete # 清理session文件 find /var/lib/php/session -name "sess_*" -type f -mtime +1 -delete可以把这些命令加到crontab里定期执行。高级排查技巧使用perf分析性能对于复杂的性能问题,可以使用perf工具进行深入分析:# 安装perf工具 yum install perf -y # 对指定进程进行采样 perf record -p 进程PID -g -- sleep 30 # 查看报告 perf reportperf可以告诉你进程把时间都花在哪里了,对于定位性能瓶颈很有帮助。使用systemtap进行动态追踪systemtap是个更强大的工具,可以动态插入探针:# 监控文件IO操作 stap -e 'probe syscall.read, syscall.write { if (pid() == target()) printf("%s: %s\n", name, argstr) }' -x 进程PID不过systemtap比较复杂,一般情况下用strace就够了。分析core dump文件如果进程崩溃了,可以通过core dump文件分析崩溃原因:# 启用core dump ulimit -c unlimited echo '/tmp/core.%e.%p' > /proc/sys/kernel/core_pattern # 使用gdb分析core文件 gdb /usr/sbin/php-fpm /tmp/core.php-fpm.12345 (gdb) bt (gdb) info registers -
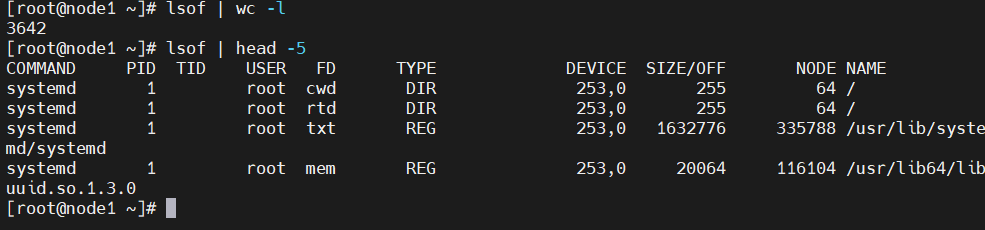
系统诊断工具lsof详解 在Linux系统中,网络连接是文件,设备是文件,管道也是文件,一切皆文件。而lsof的全称是"list open files",即列出打开的文件。因此lsof就像是系统的"透视镜",能让你看到系统内部正在发生什么。哪个进程打开了哪些文件,哪个端口被哪个程序占用,哪些文件被删除了但还在被进程使用着,这些信息lsof都能告诉你。基础用法最简单的用法就是直接输入lsof,不过这样会输出所有打开的文件,信息量太大了,一般不会这么用。输出的每一行代表一个打开的文件,包含了这些信息:COMMAND:进程名称PID:进程IDUSER:用户名FD:文件描述符TYPE:文件类型DEVICE:设备号SIZE/OFF:文件大小或偏移量NODE:inode号NAME:文件名或网络连接信息网络相关用法查看端口占用情况# 查看80端口被哪个进程占用 lsof -i:80 # 查看所有TCP连接 lsof -i tcp # 查看所有UDP连接 lsof -i udp # 查看指定IP和端口的连接 lsof -i@192.168.1.100:22查看网络连接状态# 查看所有网络连接 lsof -i # 查看指定状态的连接 lsof -i -sTCP:LISTEN # 查看监听状态的TCP连接 lsof -i -sTCP:ESTABLISHED # 查看已建立的TCP连接 #这个在排查网络问题的时候特别有用。比如怀疑某个服务连接数过多,就可以用这个命令来确认。进程相关的用法查看进程打开的文件 # 查看指定PID打开的文件 lsof -p 1234 # 查看指定进程名打开的文件 lsof -c nginx # 查看指定用户打开的文件 lsof -u www-data查看文件被哪些进程使用# 查看指定文件被哪些进程打开 lsof /var/log/nginx/access.log # 查看指定目录下的文件被哪些进程使用 lsof +D /var/log/文件系统相关找出被删除但未释放的文件 经常遇到这种情况:明明删除了大文件,但是df显示磁盘空间没有释放。这通常是因为文件被删除了,但还有进程在使用这个文件。# 查找被删除但未释放的文件 lsof | grep deleted # 或者更精确的查找 lsof +L1查看挂载点使用情况# 查看指定挂载点被哪些进程使用 lsof /mnt/data # 查看所有挂载点的使用情况 lsof -f -- /dev/sda1案例分享排查文件句柄泄漏 某个Python应用运行一段时间后就会报"Too many open files"的错误。怀疑是文件句柄泄漏。# 先找到进程PID ps aux | grep python_app # 查看进程打开的文件数量 lsof -p 12345 | wc -l # 查看具体打开了哪些文件 lsof -p 12345发现进程打开了大量的临时文件,而且数量一直在增长。最后定位到是代码里创建临时文件后没有正确清理。磁盘空间异常问题 服务器磁盘使用率突然飙升到95%,但是找不到大文件。后来用lsof发现有个日志轮转脚本有问题。排查发现有个进程打开了一个几GB的文件,但是这个文件在文件系统里找不到,原来是被删除了但进程还在写入。# 查找大文件 lsof | awk '$7 ~ /^[0-9]+$/ && $7 > 1000000 {print $2, $7, $9}' | sort -k2 -nr高级用法和技巧组合条件查询 lsof支持多种条件的组合,默认是OR关系,可以用-a参数改为AND关系。# 查看用户www-data打开的网络连接(OR关系) lsof -u www-data -i # 查看用户www-data打开的网络连接(AND关系) lsof -a -u www-data -i输出格式控制# 不显示主机名,直接显示IP lsof -n -i # 不显示端口名,直接显示端口号 lsof -P -i # 组合使用 lsof -nP -i:80这个在脚本里特别有用,因为解析主机名和端口名会比较慢。持续监控# 每2秒刷新一次 lsof -r 2 -i:80 # 监控到没有输出就退出 lsof +r 1 -i:80这个功能在调试网络连接问题的时候很有用,可以实时看到连接的变化。性能优化lsof虽然强大,但是在大型系统上运行可能会比较慢,特别是不加任何参数的时候。有几个优化技巧:尽量使用具体的参数,避免全量扫描使用-n和-P参数避免DNS和端口名解析在脚本中使用时,考虑缓存结果# 这样比较快 lsof -nP -i:80 # 这样会很慢 lsof | grep :80常见问题和注意事项使用lsof的时候有几个坑需要注意:权限问题:有些信息需要root权限才能看到系统负载:在高负载系统上运行lsof可能会影响性能输出解读:要理解各个字段的含义,特别是FD字段FD字段的含义比较复杂:cwd:当前工作目录txt:程序代码mem:内存映射文件数字:文件描述符号r、w、u:读、写、读写模式lsof的输出信息比较敏感,包含了很多系统内部的信息。在分享排查过程或者截图的时候,记得做好脱敏处理,避免泄露重要的系统信息。
-
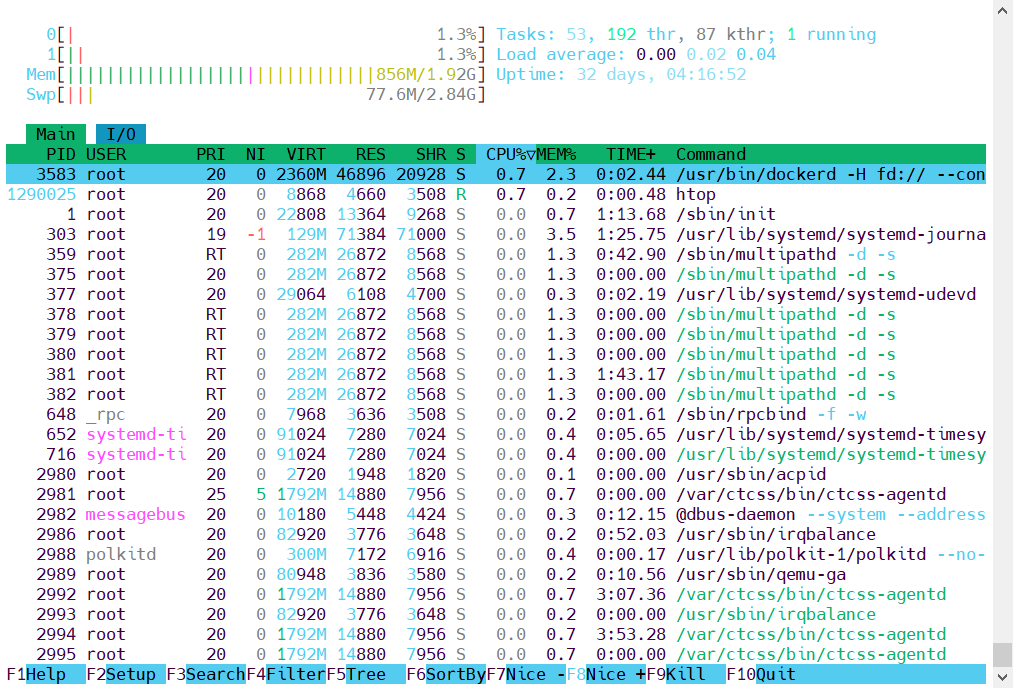
Linux常用系统监控工具介绍 在服务器管理和系统运维的日常工作中,实时监控系统资源使用情况是一项基础且关键的任务。除了比较基础的top命令外,比较常用的还有以下这些:htop:top命令的增强版glances:提供更全面的系统监控,包括网络、磁盘IO等atop:专注于长期性能监控和记录btop++:htop的现代替代品,提供更华丽的界面和更多功能iotop:专门监控磁盘IO使用情况nmon:IBM开发的系统监控工具,提供更多性能数据下面重点介绍一下htop命令。htop是一款功能强大且易于使用的Linux系统监控工具,它通过直观的界面和丰富的交互功能,大大提升了系统管理员监控和管理进程的效率。从基本的系统资源监控到复杂的进程管理,从简单的排序过滤到自定义显示配置,htop几乎能满足所有与进程监控相关的需求。在日常运维工作中,掌握htop的使用技巧不仅能帮助你快速定位系统问题,还能提高工作效率,减少排障时间。无论是处理高CPU负载、内存泄漏,还是需要快速终止失控进程,htop都能提供直观且高效的解决方案。htop界面详解运行htop时会看到一个分为上下两个部分的界面。顶部区域顶部区域显示系统的整体资源使用情况,包括:CPU使用率 每个CPU核心都有独立的使用率条,不同颜色代表不同类型的进程蓝色:低优先级进程绿色:普通用户进程红色:内核进程黄色/橙色:IRQ时间洋红色:软中断时间灰色:IO等待时间内存使用情况 显示物理内存和交换空间的使用百分比和具体数值绿色:已使用内存蓝色:缓冲区黄色/橙色:缓存负载平均值 显示1分钟、5分钟和15分钟的系统负载平均值正常运行时间 系统启动至今的运行时间任务统计 显示总进程数、运行中的进程数等信息底部区域底部区域显示系统中运行的进程列表,默认按CPU使用率排序。每个进程显示以下信息:PID:进程IDUSER:进程所有者PRI:进程优先级NI:nice值VIRT:虚拟内存大小RES:常驻内存大小SHR:共享内存大小S:进程状态(R=运行,S=睡眠,Z=僵尸等)CPU%:CPU使用百分比MEM%:内存使用百分比TIME+:进程运行时间Command:命令名称和参数htop操作技巧基本操作上下左右键:在进程列表中导航F5:切换树形视图,显示进程父子关系F6:选择排序字段F9:向进程发送信号(如终止进程)F10或q:退出htop进程管理htop最强大的功能之一是其直观的进程管理能力:终止进程:选中进程后按F9,然后选择要发送的信号(如SIGTERM或SIGKILL)调整进程优先级:选中进程后按F7(降低nice值)或F8(提高nice值)追踪进程系统调用:选中进程后按s,启动strace(需要安装strace工具)查看进程打开的文件:选中进程后按l,启动lsof(需要安装lsof工具)搜索功能在htop中,按下/键可以搜索特定进程。输入关键字后,htop会高亮显示匹配的进程。这在系统运行大量进程时特别有用。过滤功能 按下\键可以激活过滤功能,输入过滤条件后,htop只会显示符合条件的进程。例如,输入"apache"将只显示与apache相关的进程。自定义显示列 htop允许你自定义显示哪些进程信息列:按F2进入设置菜单选择"Columns"选项使用空格键选择或取消选择要显示的列F10保存并退出设置自定义配色方案如果你不喜欢默认的颜色方案,可以在设置菜单中进行更改:按F2进入设置菜单选择"Colors"选项选择预设的配色方案或自定义各元素的颜色F10保存并退出设置使用示例场景一:系统资源异常高,定位问题进程 当服务器CPU或内存使用率异常高时,可以通过以下步骤快速定位问题:启动htop,查看顶部的CPU和内存使用情况按F6,选择按CPU%或MEM%排序观察排在顶部的进程,这些通常是资源消耗最大的如果发现异常进程,可以进一步分析或终止它场景二:监控多核CPU的负载均衡情况在多核服务器上,理想情况下工作负载应该均匀分布在各个CPU核心上:启动htop,观察顶部的CPU使用率条检查各个核心的使用率是否平衡如果发现某个核心长期满负荷而其他核心空闲,可能表明应用程序不支持多线程或存在配置问题场景三:内存泄漏排查对于疑似内存泄漏的情况,可以使用htop进行初步排查:启动htop,按F6选择按MEM%排序记录可疑进程的内存使用情况定期观察这些进程的内存使用是否持续增长而不释放如果确认某进程存在内存泄漏,可以重启该进程作为临时解决方案,并进一步分析根本原因
-
-
php容器的时区设置问题 {callout color="#f0ad4e"}背景说明:如今国内开源可用的docker镜像站越发稀少,很多镜像站关闭或不在提供服务。而搭建一个网站只用到少数的几个容器如nginx、php-fpm、mysql,没必要浪费资源买一台香港服务器去拉取这些镜像。解决办法是使用了目前还算稳定的 毫秒镜像 提供的镜像服务。 在1ms.run上搜索php-fpm容器的最新版本时,发现没有官方版本,于是使用了bitnami开源组织上传的镜像bitnami/php-fpm:latest。{/callout}在bitnami提供的php-fpm镜像中,容器使用的是UTC时间,也就是协调世界时(全球时间的基准),但我们使用的CST时区(UTC+8),这里就会出现一个问题:博客的发布时间与我们所处的时区有8小时的差距。因此需要修改php-fpm的默认时区设置。进入php-fpm容器查看时区设置情况#创建一个临时容器 docker run -itd --rm docker.1ms.run/bitnami/php-fpm #进入容器查看时区设置 root@f7f574667670:/app# echo $TZ root@f7f574667670:/app# date Thu Mar 6 01:24:24 UTC 2025 #发现容器使用的是UTC时间,且没有设置TZ环境变量第一个思路,修改compose文件php-fpm容器的环境变量,设置TZ的值为Asia/Shanghaivim compose.yaml …… php8.2: container_name: php8.4 image: docker.1ms.run/bitnami/php-fpm:latest environment: - TZ=Asia/Shanghai volumes: ……为了方便验证,不用每次都去容器里面进行查看时区情况,让deepseek写了一个简单的php脚本,只要浏览器访问这个脚步就可以得到容器的时区信息。<?php // 获取当前时间和时区 $current_time = date('Y-m-d H:i:s'); // 格式化当前时间 $current_timezone = date_default_timezone_get(); // 获取当前时区 // 输出结果 echo "当前时间:$current_time\n"; echo "当前时区:$current_timezone\n"; ?> 修改完配置信息,使用浏览器验证时发现php-fpm返回的仍然是UTC时间,问题出在哪里?再次进入php容器,查看环境变量设置是否生效root@f7f574667670:/app# echo $TZ Asia/Shanghai这里发现我们设置的环境变量是生效了的,但是php-fpm返回的时间却又是UTC的,那么下一步我们就去php的配置文件中查看有没有相关设置。修改php配置,使时区设置生效查看php.ini文件时,可以发现如下默认配置项。[Date]; Defines the default timezone used by the date functions; http://php.net/date.timezone;date.timezone = UTC这里可以看到默认的时区设置,以及这个时区设置被用于date函数。因此这里的设置优先级高,可以影响到php中时间类函数获取的值。#使用php --ini命令可快速获取php配置文件的位置 #查找配置信息中含有timezone字段的配置文件 root@f7f574667670:/app# find / -maxdepth 8 -name '*.conf' -o -name '*.ini' | xargs grep timezone /opt/bitnami/php/etc/php.ini:; Defines the default timezone used by the date functions /opt/bitnami/php/etc/php.ini:; https://php.net/date.timezone /opt/bitnami/php/etc/php.ini:date.timezone = UTC /opt/bitnami/php/lib/php.ini:; Defines the default timezone used by the date functions /opt/bitnami/php/lib/php.ini:; https://php.net/date.timezone /opt/bitnami/php/lib/php.ini:date.timezone = UTC这里发现在php.ini中有一条生效的配置信息:date.timezone = UTC修改这个配置文件,把UTC修改成我们需要的时区。这里需要注意的是,如果直接把UTC改为CST,php会报错。#直接修改为CST sed -i /^date\.timezone/s/UTC/CST/ /opt/bitnami/php/lib/php.ini #让php重新加载配置 kill -USR2 $(pgrep php-fpm) #查看时区信息 php -r 'echo date_default_timezone_get();' PHP Warning: PHP Startup: Invalid date.timezone value 'CST', using 'UTC' instead in Unknown on line 0重新修改配置文件,把CST改为"Asia/Shanghai"sed -i '/^date\.timezone/s/CST/\"Asia\/Shanghai\"/' /opt/bitnami/php/lib/php.ini 或 sed -i /^date\.timezone/s%CST%\"Asia/Shanghai\"% /opt/bitnami/php/lib/php.ini #重新加载配置文件 root@f7f574667670:/app# kill -USR2 $(pgrep php-fpm) root@f7f574667670:/app# php -r 'echo date_default_timezone_get();' Asia/Shanghairoot@f7f574667670:/app# root@f7f574667670:/app# php -r "echo date('Y-m-d H:i:s');" 2025-03-06 10:44:58root@f7f574667670:/app#把php.ini文件拷贝出来,在compose文件中写入映射关系,重启php容器即可。{dotted startColor="#ff6c6c" endColor="#1989fa"/}关于php.ini-production和php.ini-development:这是php给的两个初始配置的模版,区别如下:开发环境:追求调试便利性,牺牲部分安全性。生产环境:追求安全与性能,牺牲调试信息。始终根据实际需求调整配置,两个模板文件只是起点。配置项php.ini-developmentphp.ini-production目标场景本地开发、调试环境线上生产环境错误报告显示所有错误(方便调试)隐藏错误(避免信息泄露)性能优化默认配置,无激进优化启用 opcache 等性能优化日志记录可选开启详细日志强制记录错误到日志文件安全限制较为宽松严格限制(如文件上传、执行权限)主要区别项目参数名称developmentproduction说明zend.exception_ignore_argsOffOn开启后,异常堆栈跟踪中不再显示参数的具体值,仅保留参数的类型和数量zend.exception_string_param_max_len150控制异常堆栈信息中 字符串类型参数的最大显示长度error_reportingE_ALLE_ALL & ~E_DEPRECATED前面报告所有错误,后面忽略部分警告display_errorsOnOff是否直接在页面上显示错误display_startup_errorsOnOff是否显示PHP启动过程中发生的错误mysqlnd.collect_memory_statisticsOnOff启用或禁用统计 MySQL 操作相关的内存使用数据zend.assertions1-1启用或禁用断言注:1 断言生效,检查条件并触发错误(如条件不满足)。0 生成断言代码,但不执行检查(类似注释,无性能损耗)。-1 不生成断言代码(完全忽略 assert(),性能最优,生产环境推荐)。断言(Assertion) 是开发阶段用于验证代码逻辑的调试工具