搜索到
69
篇与
的结果
-
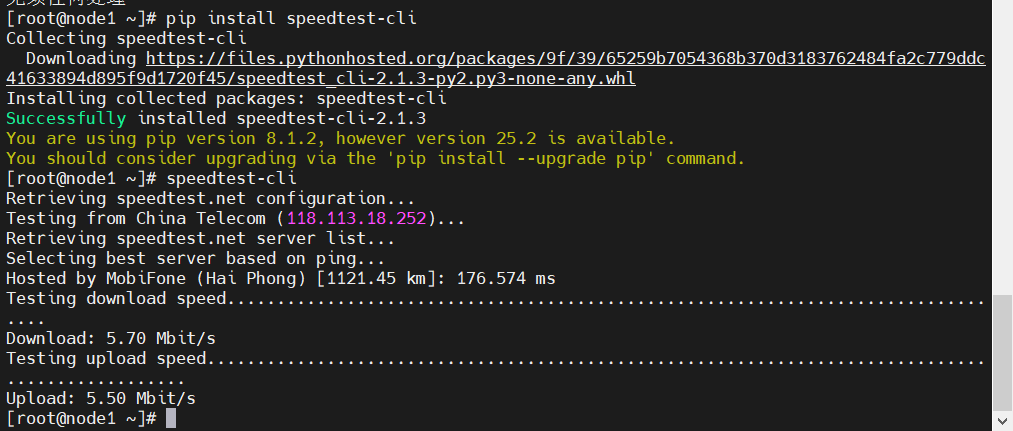
 linux中常用带宽测量工具 公网测试工具:speedtest-cli安装# CentOS/RHEL系列 yum install epel-release yum install python-pip pip install speedtest-cli # Ubuntu/Debian系列 apt update # 安装 pipx sudo apt install pipx pipx ensurepath # 安装应用 pipx install speedtest-cli运行speedtest-cli使用该命令会自动选择服务器进行测速。不过有时候自动选择的服务器不太理想,你可以手动指定。先看看附近有哪些服务器:speedtest-cli --list | grep -i China [root@node1 ~]# speedtest-cli --list | grep -i China 71313) 中国电信 (Xuzhou, China) [1301.96 km] 16204) JSQY - Suzhou (Suzhou, China) [1576.10 km] 选一个延迟比较低的:speedtest-cli --server 71313iperf3:内网测试工具speedtest-cli虽然方便,但有个问题就是测试的是到公网的速度。如果想测试内网带宽,或者两台服务器之间的带宽,那就得用iperf3了。安装iperf3# CentOS/RHEL yum install iperf3 # Ubuntu/Debian apt install iperf3测试iperf3需要一台服务器做服务端,一台做客户端。在服务端运行:iperf3 -s在客户端运行: iperf3 -c 192.168.99.100客户端结果服务端结果默认测试10秒钟,也可以指定时间:iperf3 -c 服务端IP -t 30测试UDP带宽:iperf3 -c 192.168.99.100 -u -t 15客户端结果服务端结果仔细观察上面的测试结果可以看到,测试udp的速度时网速反而比tcp的要慢很多,而正常情况是udp速度要比tcp的块。出现这种状况的原因是iperf3 中 UDP 默认带宽只有1Mbps,而TCP会自动尝试使用所有可用带宽。解决这一现象的方案是测UDP时手动设置UDP带宽。iperf3 -u -b 1G -l 1400 -c 192.168.99.100客户端服务端wget/curl - 简单实用的下载测试如果想快速测一下下载速度,不想装额外的工具,那wget和curl就够用了。下载一个100MB的文件到/dev/null(相当于丢弃),然后显示下载速度。 wget :wget -O /dev/null http://speedtest.tele2.net/100MB.zipcurlcurl -o /dev/null http://speedtest.tele2.net/100MB.zip #查看更详细的信息 curl -o /dev/null -w "下载速度: %{speed_download} bytes/sec\n总时间: %{time_total}s\n" http://speedtest.tele2.net/100MB.zip 这种方法的好处是可以测试到特定服务器的速度,比如CDN节点或者合作伙伴的服务器。nload - 实时监控网络流量安装nload# CentOS/RHEL yum install nload # Ubuntu/Debian apt install nload运行nload它会显示一个实时的图表,显示当前的上传和下载速度。如果你有多个网卡,可以用左右箭头键切换。iftop - 看看谁在占用带宽iftop比nload更进一步,它不仅能显示总的流量,还能显示每个连接的流量情况。安装CentOS/RHEL yum install iftop # Ubuntu/Debian apt install iftop运行(需要root权限)iftopiftop的界面有点像top命令,显示当前所有网络连接的流量情况。可以看到每个IP地址的上传下载速度,这对于排查网络问题特别有用。nethogs - 进程级别的网络监控安装# CentOS/RHEL yum install nethogs # Ubuntu/Debian apt install nethogs运行(需要root权限)nethogsnethogs会显示每个进程的网络使用情况,包括进程名、PID、用户等信息。这对于排查哪个应用程序占用带宽特别有用。实用的测试技巧选择合适的测试时间网络带宽测试最好在不同时间段多测几次,因为网络状况会随时间变化。我一般会在早上、中午、晚上各测一次,这样能得到比较全面的数据。注意测试方向很多人只测下载速度,忽略了上传速度。但对于服务器来说,上传速度同样重要,特别是如果你的服务器需要向用户推送大量数据的话。考虑并发连接单线程测试得到的带宽可能不能反映真实情况。可以试试多线程测试:iperf3 -c 服务端IP -P 4这个命令会启动4个并行连接进行测试。记录测试结果把测试结果记录下来,建立一个基线。这样以后出现问题的时候,你就能快速判断是不是网络带宽的问题了。如果测试结果不理想,可以按这个顺序排查:先确认是不是测试方法的问题,换个工具再测一次检查服务器的网卡配置,看看是不是限速了联系网络管理员或者运营商,确认线路状况检查防火墙和安全组设置,看看是不是有限制
linux中常用带宽测量工具 公网测试工具:speedtest-cli安装# CentOS/RHEL系列 yum install epel-release yum install python-pip pip install speedtest-cli # Ubuntu/Debian系列 apt update # 安装 pipx sudo apt install pipx pipx ensurepath # 安装应用 pipx install speedtest-cli运行speedtest-cli使用该命令会自动选择服务器进行测速。不过有时候自动选择的服务器不太理想,你可以手动指定。先看看附近有哪些服务器:speedtest-cli --list | grep -i China [root@node1 ~]# speedtest-cli --list | grep -i China 71313) 中国电信 (Xuzhou, China) [1301.96 km] 16204) JSQY - Suzhou (Suzhou, China) [1576.10 km] 选一个延迟比较低的:speedtest-cli --server 71313iperf3:内网测试工具speedtest-cli虽然方便,但有个问题就是测试的是到公网的速度。如果想测试内网带宽,或者两台服务器之间的带宽,那就得用iperf3了。安装iperf3# CentOS/RHEL yum install iperf3 # Ubuntu/Debian apt install iperf3测试iperf3需要一台服务器做服务端,一台做客户端。在服务端运行:iperf3 -s在客户端运行: iperf3 -c 192.168.99.100客户端结果服务端结果默认测试10秒钟,也可以指定时间:iperf3 -c 服务端IP -t 30测试UDP带宽:iperf3 -c 192.168.99.100 -u -t 15客户端结果服务端结果仔细观察上面的测试结果可以看到,测试udp的速度时网速反而比tcp的要慢很多,而正常情况是udp速度要比tcp的块。出现这种状况的原因是iperf3 中 UDP 默认带宽只有1Mbps,而TCP会自动尝试使用所有可用带宽。解决这一现象的方案是测UDP时手动设置UDP带宽。iperf3 -u -b 1G -l 1400 -c 192.168.99.100客户端服务端wget/curl - 简单实用的下载测试如果想快速测一下下载速度,不想装额外的工具,那wget和curl就够用了。下载一个100MB的文件到/dev/null(相当于丢弃),然后显示下载速度。 wget :wget -O /dev/null http://speedtest.tele2.net/100MB.zipcurlcurl -o /dev/null http://speedtest.tele2.net/100MB.zip #查看更详细的信息 curl -o /dev/null -w "下载速度: %{speed_download} bytes/sec\n总时间: %{time_total}s\n" http://speedtest.tele2.net/100MB.zip 这种方法的好处是可以测试到特定服务器的速度,比如CDN节点或者合作伙伴的服务器。nload - 实时监控网络流量安装nload# CentOS/RHEL yum install nload # Ubuntu/Debian apt install nload运行nload它会显示一个实时的图表,显示当前的上传和下载速度。如果你有多个网卡,可以用左右箭头键切换。iftop - 看看谁在占用带宽iftop比nload更进一步,它不仅能显示总的流量,还能显示每个连接的流量情况。安装CentOS/RHEL yum install iftop # Ubuntu/Debian apt install iftop运行(需要root权限)iftopiftop的界面有点像top命令,显示当前所有网络连接的流量情况。可以看到每个IP地址的上传下载速度,这对于排查网络问题特别有用。nethogs - 进程级别的网络监控安装# CentOS/RHEL yum install nethogs # Ubuntu/Debian apt install nethogs运行(需要root权限)nethogsnethogs会显示每个进程的网络使用情况,包括进程名、PID、用户等信息。这对于排查哪个应用程序占用带宽特别有用。实用的测试技巧选择合适的测试时间网络带宽测试最好在不同时间段多测几次,因为网络状况会随时间变化。我一般会在早上、中午、晚上各测一次,这样能得到比较全面的数据。注意测试方向很多人只测下载速度,忽略了上传速度。但对于服务器来说,上传速度同样重要,特别是如果你的服务器需要向用户推送大量数据的话。考虑并发连接单线程测试得到的带宽可能不能反映真实情况。可以试试多线程测试:iperf3 -c 服务端IP -P 4这个命令会启动4个并行连接进行测试。记录测试结果把测试结果记录下来,建立一个基线。这样以后出现问题的时候,你就能快速判断是不是网络带宽的问题了。如果测试结果不理想,可以按这个顺序排查:先确认是不是测试方法的问题,换个工具再测一次检查服务器的网卡配置,看看是不是限速了联系网络管理员或者运营商,确认线路状况检查防火墙和安全组设置,看看是不是有限制 -
服务器500错误排查指南 500错误其实就是服务器内部错误,说白了就是服务器遇到了意外情况,不知道怎么处理了。但是这个"意外情况"可能的原因太多了,从代码bug到服务器资源不足,从数据库连接问题到配置文件错误,每一个都可能是罪魁祸首。500错误虽然让人头疼,但是只要有系统的排查思路,大部分问题都能快速定位和解决。一般的排查步骤是:快速定位影响范围分析各种日志检查系统资源根据应用类型进行专项排查检查数据库连接排查配置和环境问题检查网络和依赖服务不同技术栈的应用有不同的排查重点,Java应用重点关注JVM内存和GC,PHP应用重点关注进程和权限,Python应用重点关注模块导入和WSGI服务器,Go应用重点关注goroutine泄漏,Node.js应用重点关注事件循环阻塞。排查问题的时候要保持冷静,按照步骤一步步来。不要一上来就乱改配置,那样可能会让问题变得更复杂。最重要的是,要从每次故障中学习,不断完善监控和预防措施。第一步:快速定位问题范围遇到500错误,首先搞清楚影响范围。这个很重要,因为它决定了你处理问题的优先级和方式。是所有页面都500还是只有特定页面(可以通过浏览器f12查看报错接口)是所有用户都受影响还是部分用户错误是突然出现的还是逐渐增多的案例:某个业务网站突然开始报500错误。先测试几个不同的页面,发现只有特定页有问题,首页和其他功能页面都正常。这就大大缩小了排查范围,基本可以确定是相关的功能出了问题。如果使用了负载均衡,还要检查一下是不是某台服务器的问题。一般可用直接访问每台服务器的IP,看看是不是所有服务器都有问题。有时候可能只是其中一台服务器出了状况。第二步:深入日志分析确定了影响范围之后,就该看日志了。日志是我们排查问题最重要的线索,但是看日志也有技巧。Web服务器日志先看Web服务器的错误日志,比如Nginx的error.log或者Apache的error_log。这里通常能看到最直接的错误信息。tail -f /var/log/nginx/error.log经常遇到的错误类型有:连接超时:upstream timed out连接被拒绝:connect() failed (111: Connection refused)文件权限问题:Permission denied配置语法错误:nginx configuration test failed案例:Nginx日志显示"upstream timed out",但是应用服务器看起来运行正常。后来发现是因为某个接口的处理时间突然变长了,超过了Nginx设置的超时时间。调整了一下proxy_read_timeout就解决了。第三步:系统资源检查有时候500错误不是代码问题,而是服务器资源不够用了。这种情况下,即使代码没问题,服务器也处理不了请求。内存使用情况free -h如果可用内存很少,或者swap使用率很高,那很可能就是内存不足导致的问题。特别是在流量突然增大的时候,因为内存不足导致500错误发生的几率会高很多。还可以用top或者htop看看哪个进程占用内存最多:top -o %MEMCPU使用率topCPU使用率持续100%也会导致服务器响应缓慢或者直接返回500错误。有些服务器因为某个进程死循环,CPU占用率一直是100%,导致整个网站都访问不了。磁盘空间df -h磁盘空间不足也是一个常见原因,特别是日志文件增长太快的时候。比如因为某个日志文件疯狂增长,把磁盘空间占满了,导致应用无法写入临时文件而报500错误。不同应用类型的专项排查不同技术栈的应用出现500错误时,排查重点还是有些区别的。Java应用排查Java应用的500错误排查,一般从这几个方面入手:JVM内存问题 Java应用最容易出现的就是内存问题,特别是OutOfMemoryError。jstat -gc <pid> jmap -histo <pid>某次一个Spring Boot应用突然开始频繁500,通过jstat发现老年代内存使用率一直在99%以上,明显是内存泄漏了。后来用MAT分析heap dump,发现是某个缓存没有设置过期时间,导致对象越积累越多。线程池状态jstack <pid>线程池满了也会导致请求无法处理。有些应用因为某个接口响应特别慢,把线程池都占满了,新的请求进来就直接500了。GC问题jstat -gc <pid> 1s如果Full GC频繁或者GC时间过长,也会影响应用响应。如果应用每隔几分钟就会卡顿几秒钟,用户访问就会超时报500,原因就是Full GC时间太长了。应用日志 Java应用的日志通常在logs目录下,或者通过logback、log4j配置的路径:tail -f /app/logs/application.log grep "ERROR" /app/logs/application.log | tail -20常见的错误类型:数据库连接池耗尽空指针异常类加载失败配置文件读取失败PHP应用排查PHP应用的排查相对简单一些,但也有自己的特点。PHP-FPM进程状态systemctl status php-fpm ps aux | grep php-fpmPHP-FPM进程数不够或者进程死掉了,都会导致500错误。有时是因为php-fpm配置的max_children太小,高并发时进程不够用的情况。PHP错误日志tail -f /var/log/php/error.logPHP的错误日志通常能直接告诉你问题所在:Fatal error: 致命错误,比如内存不足、语法错误Parse error: 语法解析错误Warning: 警告,可能导致功能异常内存限制PHP有memory_limit限制,如果脚本占用内存超过这个值就会报Fatal error:php -i | grep memory_limit有些数据导入脚本,处理大文件时内存不够用,直接就500了。文件权限 PHP应用对文件权限比较敏感,特别是上传目录、缓存目录等:ls -la /var/www/html/Python应用排查Python应用的排查重点又不太一样。WSGI服务器状态 如果用的是Gunicorn或者uWSGI:ps aux | grep gunicorn systemctl status gunicornPython进程内存 Python应用也容易出现内存泄漏,特别是使用了某些C扩展的时候:ps -o pid,ppid,cmd,%mem,%cpu --sort=-%mem | headDjango/Flask应用日志tail -f /var/log/django/error.log tail -f /var/log/flask/app.logPython应用常见的500错误:模块导入失败数据库连接问题模板渲染错误第三方库版本冲突案例:服务器上同时跑着Python 2和Python 3的应用,结果某次系统更新后,Python 2的一些依赖包出问题了,导致应用启动失败。Go应用排查Go应用相对来说比较稳定,但也有自己的问题。Goroutine泄漏curl http://localhost:6060/debug/pprof/goroutine?debug=1如果开启了pprof,可以通过这个接口查看goroutine数量。goroutine泄漏会导致内存占用越来越高。应用日志 Go应用的日志格式比较自由,通常在应用目录或者系统日志里:journalctl -u your-go-app -f tail -f /var/log/your-app.logpanic恢复 Go应用如果没有正确处理panic,就会导致整个程序崩溃:defer func() { if r := recover(); r != nil { log.Printf("Recovered from panic: %v", r) } }()Node.js应用排查Node.js应用的排查也有自己的特点。进程管理器状态 如果用的是PM2:pm2 status pm2 logs内存泄漏检查 Node.js应用容易出现内存泄漏,特别是事件监听器没有正确移除的时候:node --inspect your-app.js然后用Chrome DevTools连接进行内存分析。事件循环阻塞const blocked = require('blocked-at'); blocked((time, stack) => { console.log(`Blocked for ${time}ms, operation started here:`, stack); });数据库连接问题排查数据库问题是导致500错误的一个大头。我遇到的数据库相关的500错误主要有几种:连接数耗尽SHOW PROCESSLIST; SHOW STATUS LIKE 'Threads_connected'; SHOW VARIABLES LIKE 'max_connections';如果连接数接近max_connections的值,就说明数据库连接池满了。这时候新的请求就会因为无法获取数据库连接而报500错误。一次双11活动,流量突然暴增,数据库连接数瞬间就满了。当时紧急调整了max_connections的值,同时优化了应用的连接池配置,才解决了问题。慢查询SHOW PROCESSLIST;如果看到很多查询处于"Sending data"或者"Copying to tmp table"状态,说明有慢查询在拖累整个数据库性能。可以开启慢查询日志来定位具体是哪些SQL语句有问题:SET GLOBAL slow_query_log = 'ON'; SET GLOBAL long_query_time = 2;锁等待SHOW ENGINE INNODB STATUS;这个命令可以看到InnoDB的详细状态,包括是否有死锁或者锁等待的情况。配置文件和环境问题配置文件的问题也经常导致500错误,而且这种问题通常比较隐蔽。Web服务器配置 检查Nginx或Apache的配置文件语法:nginx -t apache2ctl configtest我见过有人修改配置文件后忘记检查语法,重启服务后直接就500了。还有一种情况是配置文件的路径写错了,或者权限设置不对。应用配置 应用程序的配置文件也要检查,比如数据库连接配置、缓存配置等。有时候可能是配置文件被意外修改了,或者环境变量没有正确设置。一次很坑的情况:开发同事在测试环境修改了数据库配置,结果不小心把生产环境的配置也改了,导致应用连不上数据库,全站500。环境变量 很多现代应用都依赖环境变量来配置:env | grep APP_ printenv特别是容器化部署的应用,环境变量配置错误是常见的500错误原因。网络和依赖服务问题 有时候500错误不是应用本身的问题,而是依赖的外部服务出了问题。第三方API 现在的应用很少是完全独立的,通常都会调用各种第三方API。如果这些API出问题了,也可能导致应用报500错误。我建议在调用第三方API的时候一定要做好异常处理和超时设置:import requests from requests.exceptions import RequestException, Timeout try: response = requests.get(api_url, timeout=5) response.raise_for_status() except Timeout: # 处理超时,返回默认值或降级处理 return default_response except RequestException as e: # 处理其他请求异常 logger.error(f"API调用失败: {e}") return error_response内部服务依赖 如果是微服务架构,要检查各个服务之间的调用是否正常:curl -I http://internal-service:8080/health telnet internal-service 8080案例:用户服务突然开始报500,排查了半天发现是依赖的订单服务挂了。这种情况下,最好是有熔断机制,避免级联故障。DNS解析 有时候DNS解析出问题也会导致服务调用失败:nslookup your-service-domain dig your-service-domain比如内部DNS服务器不稳定,偶尔会解析失败,导致应用无法连接到数据库或者其他服务。实战案例分享案例一:Java应用内存泄漏有一次一个Spring Boot应用开始间歇性500错误,刚开始以为是偶发问题,但是随着时间推移,错误频率越来越高。排查过程是这样的:检查了应用日志,发现有OutOfMemoryError用jstat查看GC情况,发现老年代内存使用率持续上升生成heap dump进行分析,发现某个Map对象占用了大量内存代码review发现是缓存没有设置过期策略最后给缓存添加了LRU策略和过期时间,问题就解决了。这个案例告诉我们,缓存虽然能提高性能,但是一定要合理设置过期策略。案例二:PHP-FPM进程不足这是一个WordPress网站,在某次营销活动后开始频繁500错误。排查步骤:检查Nginx日志,发现大量"upstream timed out"查看PHP-FPM状态,发现进程数已经达到上限检查PHP-FPM配置,max_children设置得太小了调整配置后重启服务,问题解决这个案例说明容量规划很重要,要根据实际业务量来调整配置。案例三:Python应用模块导入失败某次一个Django应用突然开始500,但是重启后又正常了,过一段时间又开始500。最后发现是某个Python包的版本有问题,在特定条件下会导入失败。这种间歇性的问题最难排查,需要仔细分析日志中的错误模式。案例四:Go应用goroutine泄漏这是一个Go写的API服务,运行一段时间后开始出现500错误。通过pprof发现goroutine数量异常增多,最后定位到某个HTTP客户端没有正确设置超时,导致goroutine一直阻塞。案例五:Node.js事件循环阻塞一个Node.js应用,用户反馈页面加载很慢,有时候会500。用blocked模块检测发现事件循环被阻塞,原因是某个同步文件操作阻塞了事件循环。改为异步操作后问题解决。工具推荐最后推荐一些常用的排查工具:系统监控htop: 更好用的topiotop: 磁盘IO监控nethogs: 网络流量监控dstat: 综合系统监控日志分析ELK Stack: Elasticsearch + Logstash + KibanaFluentd: 日志收集Loki: 轻量级日志系统应用监控Prometheus: 指标收集Grafana: 可视化Jaeger: 分布式追踪APM工具: New Relic、DataDog、Skywalking数据库监控pt-query-digest: MySQL慢查询分析pgbadger: PostgreSQL日志分析Redis监控: redis-cli --latency工具只是辅助,关键还是要有正确的排查思路。
-
PHP-FPM进程假死问题处理思路 进程假死其实就是进程还在,但是不干活了。用ps命令看,进程确实存在,但就是不处理请求。PHP-FPM作为FastCGI进程管理器,负责管理PHP进程池。当它出现假死时,表现就是:进程存在但不响应新请求CPU使用率可能很低或者异常高内存占用可能持续增长日志可能停止更新或者出现异常快速定位和解决进程假死问题,关键是要:建立完善的监控体系,及时发现问题熟练掌握各种排查工具的使用针对常见场景做好预防措施特别要重视磁盘IO问题,这个经常被忽略但影响很大保持冷静,按照既定流程逐步排查磁盘IO问题特别值得重视,因为它往往比较隐蔽,不像CPU或内存问题那么明显。很多时候系统看起来资源充足,但就是响应慢,这时候就要想到是不是磁盘IO的问题了。快速判断是否为进程假死看进程状态ps aux | grep php-fpm正常情况下的输出如下:如果看到进程状态是D(不可中断睡眠)或者Z(僵尸进程),那基本就是有问题了。STAT: 进程状态码S: 睡眠状态s: 会话领导者l: 多线程+: 前台进程组R: 运行中D 状态的进程通常是在等待 I/O 操作完成,如磁盘读写Z 状态 (僵尸进程),僵尸进程是已经终止但父进程尚未调用 wait() 获取其退出状态的进程检查进程响应# 查看PHP-FPM状态页面(需要先配置) curl http://localhost/status # 或者直接测试PHP页面响应 curl -w "@curl-format.txt" -o /dev/null -s "http://your-site.com/test.php"如果curl一直卡住不返回,或者返回时间特别长,那就很可能是假死了。观察系统资源# 查看CPU使用情况 top -p `pgrep php-fpm | tr '\n' ',' | sed 's/,$//'` # 查看内存使用 free -h # 查看磁盘IO iostat -x 1深入分析假死原因strace可以实时查看进程在做什么系统调用:# 找到问题进程PID ps aux | grep php-fpm | grep -v master # 追踪系统调用 strace -p 进程PID -f -e trace=all查看进程调用栈如果strace信息太多看不过来,可以用gdb查看调用栈gdb -p 进程PID (gdb) bt (gdb) info threads (gdb) thread apply all bt分析PHP-FPM慢日志PHP-FPM有个很有用的功能就是慢日志,可以记录执行时间超过阈值的请求:在php-fpm.conf中配置 slowlog = /var/log/php-fpm/slow.log request_slowlog_timeout = 5s慢日志会记录详细的调用栈,比如: [26-Oct-2024 15:30:45] [pool www] pid 12345 script_filename = /var/www/html/index.php [0x00007f8b8c0c8000] curl_exec() /var/www/html/api.php:45 [0x00007f8b8c0c8100] api_call() /var/www/html/index.php:23 通过慢日志能很快定位到是哪个函数卡住了。常见的假死场景和解决方案数据库连接问题这个真的太常见了。数据库连接池满了,或者网络抖动,都可能导致PHP进程卡在数据库操作上。解决方案:设置合理的数据库连接超时时间使用连接池,避免频繁建立连接监控数据库连接数设置MySQL连接超时 $pdo = new PDO($dsn, $user, $pass, [ PDO::ATTR_TIMEOUT => 5, PDO::MYSQL_ATTR_INIT_COMMAND => "SET SESSION wait_timeout=30"外部API调用超时调用第三方API时没设置超时,对方服务挂了你也跟着挂。我见过太多这种情况了,一个支付接口的问题导致整个网站瘫痪。#使用curl时一定要设置超时 $ch = curl_init(); curl_setopt($ch, CURLOPT_TIMEOUT, 10); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 5);文件锁竞争多个进程同时操作同一个文件,可能导致死锁:#使用flock时要注意超时 $fp = fopen('data.txt', 'w'); if (flock($fp, LOCK_EX | LOCK_NB)) { // 获得锁,执行操作 fwrite($fp, $data); flock($fp, LOCK_UN); } else { // 获取锁失败,记录日志或者返回错误 error_log('Failed to acquire file lock'); } fclose($fp);磁盘IO问题导致的假死这个问题特别隐蔽,经常被忽略。磁盘IO性能差或者磁盘故障,会导致进程卡在文件读写操作上。#快速检测磁盘IO问题 # 查看磁盘IO使用率 iostat -x 1 5重点关注这几个指标:%util - 磁盘使用率,接近100%说明磁盘很忙await - 平均等待时间,超过20ms就要注意了svctm - 平均服务时间案例:服务器磁盘的%util一直在99%以上,但是通过top看CPU使用率很低。后来发现是磁盘坏道导致的,读写特别慢。找出占用IO的进程 # 安装iotop工具 apt install iotop -y # 实时查看IO使用情况 iotop -o -d 1 # 或者使用pidstat pidstat -d 1iotop的输出类似这样:Total DISK READ : 0.00 B/s | Total DISK WRITE : 12.34 M/s Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 15.67 M/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 1234 be/4 www 0.00 B/s 10.23 M/s 0.00 % 85.67 % php-fpm: pool www如果看到某个PHP-FPM进程的IO使用率特别高,那就要重点关注了。分析具体的文件操作# 使用lsof查看进程打开的文件 lsof -p 进程PID # 或者查看进程的文件描述符 ls -la /proc/进程PID/fd/案例:PHP程序在写日志时没有正确关闭文件句柄,导致同一个日志文件被打开了几千次,磁盘IO直接爆炸。磁盘空间不足的问题# 检查磁盘使用情况 df -h # 查找大文件 find /var/log -type f -size +100M -exec ls -lh {} \; # 查看目录大小 du -sh /var/log/*磁盘空间不足时,写操作会变得特别慢,甚至失败。PHP-FPM进程可能会卡在日志写入或者临时文件创建上。内存泄漏导致的假死PHP进程内存使用过多,触发系统的OOM机制,进程就卡住了。可以通过以下方式监控:# 查看进程内存使用 cat /proc/进程PID/status | grep VmRSS # 或者用ps ps -o pid,vsz,rss,comm -p 进程PID应急处理方案重启PHP-FPM服务# CentOS/RHEL systemctl restart php-fpm # Ubuntu/Debian systemctl restart php7.4-fpm # 或者直接kill掉重启 pkill php-fpm /usr/sbin/php-fpm -D不过重启会中断正在处理的请求,生产环境要慎重。平滑重启PHP-FPM支持平滑重启,不会中断现有连接:# 发送USR2信号进行平滑重启 kill -USR2 `cat /var/run/php-fpm.pid` # 或者使用systemctl systemctl reload php-fpm预防措施监控日志记录开启详细的日志记录,方便问题排查:php-fpm.conf log_level = notice access.log = /var/log/php-fpm/access.log access.format = "%R - %u %t \"%m %r\" %s %f %{mili}d %{kilo}M %C%%"定期重启一些老项目可能存在内存泄漏问题,可以设置定期重启# 添加到crontab,每天凌晨3点重启 0 3 * * * /usr/bin/systemctl reload php-fpm注意事项不要随便kill -9很多人遇到进程假死第一反应就是kill -9,但这样可能会导致数据不一致。最好先尝试kill -TERM让进程优雅退出。注意PHP-FPM版本差异不同版本的PHP-FPM配置参数可能不一样,升级时要注意兼容性。我就遇到过从PHP 7.2升级到7.4后,原来的配置不生效的情况。监控指标要合理设置监控阈值时不要太敏感,否则会产生很多误报。我之前设置响应时间超过1秒就告警,结果每天收到几十条告警消息,后来调整到5秒才比较合理。磁盘IO监控容易被忽略很多人只关注CPU和内存,忽略了磁盘IO。其实磁盘IO问题导致的服务假死非常常见,特别是那些有大量文件操作的应用。建议在监控系统中加入这些磁盘相关的指标:磁盘使用率(%util)平均等待时间(await)磁盘空间使用率inode使用率日志轮转PHP-FPM的日志文件会越来越大,一定要配置logrotate进行日志轮转,否则磁盘满了又是另一个问题。# /etc/logrotate.d/php-fpm /var/log/php-fpm/*.log { daily missingok rotate 7 compress delaycompress notifempty postrotate /bin/kill -USR1 `cat /var/run/php-fpm.pid 2>/dev/null` 2>/dev/null || true endscript }临时文件清理PHP会在/tmp目录下创建临时文件,如果程序异常退出,这些临时文件可能不会被清理。时间长了会占用大量磁盘空间和inode。# 定期清理PHP临时文件 find /tmp -name "php*" -type f -mtime +1 -delete # 清理session文件 find /var/lib/php/session -name "sess_*" -type f -mtime +1 -delete可以把这些命令加到crontab里定期执行。高级排查技巧使用perf分析性能对于复杂的性能问题,可以使用perf工具进行深入分析:# 安装perf工具 yum install perf -y # 对指定进程进行采样 perf record -p 进程PID -g -- sleep 30 # 查看报告 perf reportperf可以告诉你进程把时间都花在哪里了,对于定位性能瓶颈很有帮助。使用systemtap进行动态追踪systemtap是个更强大的工具,可以动态插入探针:# 监控文件IO操作 stap -e 'probe syscall.read, syscall.write { if (pid() == target()) printf("%s: %s\n", name, argstr) }' -x 进程PID不过systemtap比较复杂,一般情况下用strace就够了。分析core dump文件如果进程崩溃了,可以通过core dump文件分析崩溃原因:# 启用core dump ulimit -c unlimited echo '/tmp/core.%e.%p' > /proc/sys/kernel/core_pattern # 使用gdb分析core文件 gdb /usr/sbin/php-fpm /tmp/core.php-fpm.12345 (gdb) bt (gdb) info registers
-
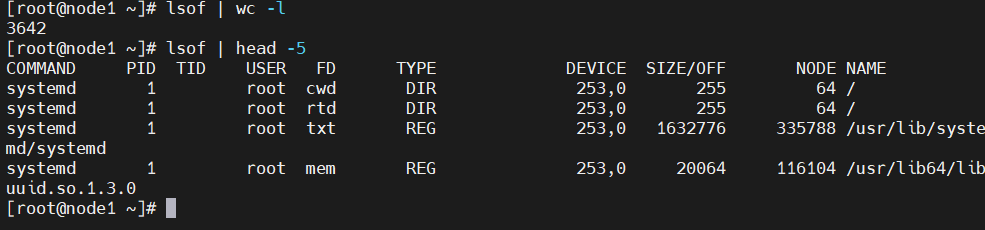
系统诊断工具lsof详解 在Linux系统中,网络连接是文件,设备是文件,管道也是文件,一切皆文件。而lsof的全称是"list open files",即列出打开的文件。因此lsof就像是系统的"透视镜",能让你看到系统内部正在发生什么。哪个进程打开了哪些文件,哪个端口被哪个程序占用,哪些文件被删除了但还在被进程使用着,这些信息lsof都能告诉你。基础用法最简单的用法就是直接输入lsof,不过这样会输出所有打开的文件,信息量太大了,一般不会这么用。输出的每一行代表一个打开的文件,包含了这些信息:COMMAND:进程名称PID:进程IDUSER:用户名FD:文件描述符TYPE:文件类型DEVICE:设备号SIZE/OFF:文件大小或偏移量NODE:inode号NAME:文件名或网络连接信息网络相关用法查看端口占用情况# 查看80端口被哪个进程占用 lsof -i:80 # 查看所有TCP连接 lsof -i tcp # 查看所有UDP连接 lsof -i udp # 查看指定IP和端口的连接 lsof -i@192.168.1.100:22查看网络连接状态# 查看所有网络连接 lsof -i # 查看指定状态的连接 lsof -i -sTCP:LISTEN # 查看监听状态的TCP连接 lsof -i -sTCP:ESTABLISHED # 查看已建立的TCP连接 #这个在排查网络问题的时候特别有用。比如怀疑某个服务连接数过多,就可以用这个命令来确认。进程相关的用法查看进程打开的文件 # 查看指定PID打开的文件 lsof -p 1234 # 查看指定进程名打开的文件 lsof -c nginx # 查看指定用户打开的文件 lsof -u www-data查看文件被哪些进程使用# 查看指定文件被哪些进程打开 lsof /var/log/nginx/access.log # 查看指定目录下的文件被哪些进程使用 lsof +D /var/log/文件系统相关找出被删除但未释放的文件 经常遇到这种情况:明明删除了大文件,但是df显示磁盘空间没有释放。这通常是因为文件被删除了,但还有进程在使用这个文件。# 查找被删除但未释放的文件 lsof | grep deleted # 或者更精确的查找 lsof +L1查看挂载点使用情况# 查看指定挂载点被哪些进程使用 lsof /mnt/data # 查看所有挂载点的使用情况 lsof -f -- /dev/sda1案例分享排查文件句柄泄漏 某个Python应用运行一段时间后就会报"Too many open files"的错误。怀疑是文件句柄泄漏。# 先找到进程PID ps aux | grep python_app # 查看进程打开的文件数量 lsof -p 12345 | wc -l # 查看具体打开了哪些文件 lsof -p 12345发现进程打开了大量的临时文件,而且数量一直在增长。最后定位到是代码里创建临时文件后没有正确清理。磁盘空间异常问题 服务器磁盘使用率突然飙升到95%,但是找不到大文件。后来用lsof发现有个日志轮转脚本有问题。排查发现有个进程打开了一个几GB的文件,但是这个文件在文件系统里找不到,原来是被删除了但进程还在写入。# 查找大文件 lsof | awk '$7 ~ /^[0-9]+$/ && $7 > 1000000 {print $2, $7, $9}' | sort -k2 -nr高级用法和技巧组合条件查询 lsof支持多种条件的组合,默认是OR关系,可以用-a参数改为AND关系。# 查看用户www-data打开的网络连接(OR关系) lsof -u www-data -i # 查看用户www-data打开的网络连接(AND关系) lsof -a -u www-data -i输出格式控制# 不显示主机名,直接显示IP lsof -n -i # 不显示端口名,直接显示端口号 lsof -P -i # 组合使用 lsof -nP -i:80这个在脚本里特别有用,因为解析主机名和端口名会比较慢。持续监控# 每2秒刷新一次 lsof -r 2 -i:80 # 监控到没有输出就退出 lsof +r 1 -i:80这个功能在调试网络连接问题的时候很有用,可以实时看到连接的变化。性能优化lsof虽然强大,但是在大型系统上运行可能会比较慢,特别是不加任何参数的时候。有几个优化技巧:尽量使用具体的参数,避免全量扫描使用-n和-P参数避免DNS和端口名解析在脚本中使用时,考虑缓存结果# 这样比较快 lsof -nP -i:80 # 这样会很慢 lsof | grep :80常见问题和注意事项使用lsof的时候有几个坑需要注意:权限问题:有些信息需要root权限才能看到系统负载:在高负载系统上运行lsof可能会影响性能输出解读:要理解各个字段的含义,特别是FD字段FD字段的含义比较复杂:cwd:当前工作目录txt:程序代码mem:内存映射文件数字:文件描述符号r、w、u:读、写、读写模式lsof的输出信息比较敏感,包含了很多系统内部的信息。在分享排查过程或者截图的时候,记得做好脱敏处理,避免泄露重要的系统信息。
-
服务器故障的一般排查流程 当服务出现故障时,比如服务不可达,无法远程访问,应用程序报错等故障时,常用的排查思路整理如下。确定故障和检查硬件当发现服务器出现故障时,应详细记录故障发生的具体情况。包括:故障发生时间,故障发生规律,故障是否具有规律性等故障的具体表现,如服务器无法连接,应用程序报错,端口未开放等故障发生前是否有特殊操作,如系统更新,软件安装,修改配置等如果使用的不是云服务器而是自有硬件,还需要检查硬件设置状态查看服务器电源指示灯是否正常,硬盘指示灯是否有异常闪烁,cpu风扇是否正常运转,是否有异响或异味。检查交换机、路由器等常用网络设备是否存在异常,检查网络设备的指示灯状态,确认网线连接是否牢固。若服务器配备硬件监控系统,登录查看硬件健康状态报告,排查是否有硬盘故障,内存报错,电源问题等。验证是否存在网络问题本地网络测试:在服务器本地使用ping命令测试与网关、DNS服务器的连通性,检查防火墙。远程连接测试:从客户端尝试ping服务器ip,使用traceroute命令追踪路由,判断故障节点。端口状态检查:在服务器上使用netstat或者ss命令查看端口的监听状态,确认应用程序所需端口是否正常开放。查看、分析日志查看系统生成的各种日志文件,定位故障发生的原因,比如/var/log/messages(系统通用日志),/var/log/auth.log(认证相关日志)等,使用grep筛选关键词(如error、fail)快速定位问题。针对服务器上运行的应用程序(如web服务,数据库。中间件等),查看其专属日志。如,web服务,Nginx日志通常在/var/log/nginx/access.log和error.log,apache日志在/var/log/apache2/目录下。或者去配置文件中查看日志路径,在对日志文件进行排查。数据库,mysql日志包括错误日志,慢查询日志等。尝试重启服务或设备重启服务:若定位到某一服务异常,先尝试重启该服务观察是否恢复正常。重启服务器:排除掉硬件故障风险后,可以尝试重启服务器,在重新启动服务来观察是否恢复正常。(需提前通知相关用户,避免数据丢失)。