搜索到
92
篇与
的结果
-
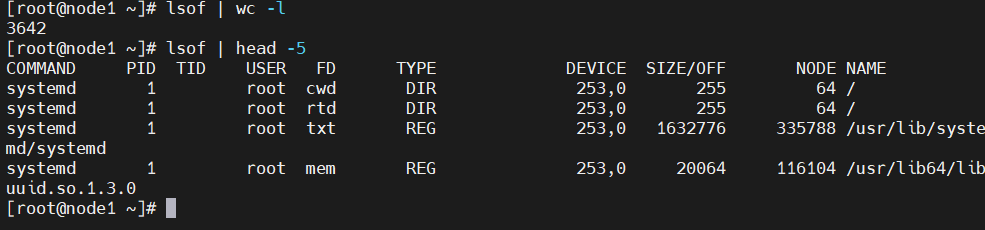
 系统诊断工具lsof详解 在Linux系统中,网络连接是文件,设备是文件,管道也是文件,一切皆文件。而lsof的全称是"list open files",即列出打开的文件。因此lsof就像是系统的"透视镜",能让你看到系统内部正在发生什么。哪个进程打开了哪些文件,哪个端口被哪个程序占用,哪些文件被删除了但还在被进程使用着,这些信息lsof都能告诉你。基础用法最简单的用法就是直接输入lsof,不过这样会输出所有打开的文件,信息量太大了,一般不会这么用。输出的每一行代表一个打开的文件,包含了这些信息:COMMAND:进程名称PID:进程IDUSER:用户名FD:文件描述符TYPE:文件类型DEVICE:设备号SIZE/OFF:文件大小或偏移量NODE:inode号NAME:文件名或网络连接信息网络相关用法查看端口占用情况# 查看80端口被哪个进程占用 lsof -i:80 # 查看所有TCP连接 lsof -i tcp # 查看所有UDP连接 lsof -i udp # 查看指定IP和端口的连接 lsof -i@192.168.1.100:22查看网络连接状态# 查看所有网络连接 lsof -i # 查看指定状态的连接 lsof -i -sTCP:LISTEN # 查看监听状态的TCP连接 lsof -i -sTCP:ESTABLISHED # 查看已建立的TCP连接 #这个在排查网络问题的时候特别有用。比如怀疑某个服务连接数过多,就可以用这个命令来确认。进程相关的用法查看进程打开的文件 # 查看指定PID打开的文件 lsof -p 1234 # 查看指定进程名打开的文件 lsof -c nginx # 查看指定用户打开的文件 lsof -u www-data查看文件被哪些进程使用# 查看指定文件被哪些进程打开 lsof /var/log/nginx/access.log # 查看指定目录下的文件被哪些进程使用 lsof +D /var/log/文件系统相关找出被删除但未释放的文件 经常遇到这种情况:明明删除了大文件,但是df显示磁盘空间没有释放。这通常是因为文件被删除了,但还有进程在使用这个文件。# 查找被删除但未释放的文件 lsof | grep deleted # 或者更精确的查找 lsof +L1查看挂载点使用情况# 查看指定挂载点被哪些进程使用 lsof /mnt/data # 查看所有挂载点的使用情况 lsof -f -- /dev/sda1案例分享排查文件句柄泄漏 某个Python应用运行一段时间后就会报"Too many open files"的错误。怀疑是文件句柄泄漏。# 先找到进程PID ps aux | grep python_app # 查看进程打开的文件数量 lsof -p 12345 | wc -l # 查看具体打开了哪些文件 lsof -p 12345发现进程打开了大量的临时文件,而且数量一直在增长。最后定位到是代码里创建临时文件后没有正确清理。磁盘空间异常问题 服务器磁盘使用率突然飙升到95%,但是找不到大文件。后来用lsof发现有个日志轮转脚本有问题。排查发现有个进程打开了一个几GB的文件,但是这个文件在文件系统里找不到,原来是被删除了但进程还在写入。# 查找大文件 lsof | awk '$7 ~ /^[0-9]+$/ && $7 > 1000000 {print $2, $7, $9}' | sort -k2 -nr高级用法和技巧组合条件查询 lsof支持多种条件的组合,默认是OR关系,可以用-a参数改为AND关系。# 查看用户www-data打开的网络连接(OR关系) lsof -u www-data -i # 查看用户www-data打开的网络连接(AND关系) lsof -a -u www-data -i输出格式控制# 不显示主机名,直接显示IP lsof -n -i # 不显示端口名,直接显示端口号 lsof -P -i # 组合使用 lsof -nP -i:80这个在脚本里特别有用,因为解析主机名和端口名会比较慢。持续监控# 每2秒刷新一次 lsof -r 2 -i:80 # 监控到没有输出就退出 lsof +r 1 -i:80这个功能在调试网络连接问题的时候很有用,可以实时看到连接的变化。性能优化lsof虽然强大,但是在大型系统上运行可能会比较慢,特别是不加任何参数的时候。有几个优化技巧:尽量使用具体的参数,避免全量扫描使用-n和-P参数避免DNS和端口名解析在脚本中使用时,考虑缓存结果# 这样比较快 lsof -nP -i:80 # 这样会很慢 lsof | grep :80常见问题和注意事项使用lsof的时候有几个坑需要注意:权限问题:有些信息需要root权限才能看到系统负载:在高负载系统上运行lsof可能会影响性能输出解读:要理解各个字段的含义,特别是FD字段FD字段的含义比较复杂:cwd:当前工作目录txt:程序代码mem:内存映射文件数字:文件描述符号r、w、u:读、写、读写模式lsof的输出信息比较敏感,包含了很多系统内部的信息。在分享排查过程或者截图的时候,记得做好脱敏处理,避免泄露重要的系统信息。
系统诊断工具lsof详解 在Linux系统中,网络连接是文件,设备是文件,管道也是文件,一切皆文件。而lsof的全称是"list open files",即列出打开的文件。因此lsof就像是系统的"透视镜",能让你看到系统内部正在发生什么。哪个进程打开了哪些文件,哪个端口被哪个程序占用,哪些文件被删除了但还在被进程使用着,这些信息lsof都能告诉你。基础用法最简单的用法就是直接输入lsof,不过这样会输出所有打开的文件,信息量太大了,一般不会这么用。输出的每一行代表一个打开的文件,包含了这些信息:COMMAND:进程名称PID:进程IDUSER:用户名FD:文件描述符TYPE:文件类型DEVICE:设备号SIZE/OFF:文件大小或偏移量NODE:inode号NAME:文件名或网络连接信息网络相关用法查看端口占用情况# 查看80端口被哪个进程占用 lsof -i:80 # 查看所有TCP连接 lsof -i tcp # 查看所有UDP连接 lsof -i udp # 查看指定IP和端口的连接 lsof -i@192.168.1.100:22查看网络连接状态# 查看所有网络连接 lsof -i # 查看指定状态的连接 lsof -i -sTCP:LISTEN # 查看监听状态的TCP连接 lsof -i -sTCP:ESTABLISHED # 查看已建立的TCP连接 #这个在排查网络问题的时候特别有用。比如怀疑某个服务连接数过多,就可以用这个命令来确认。进程相关的用法查看进程打开的文件 # 查看指定PID打开的文件 lsof -p 1234 # 查看指定进程名打开的文件 lsof -c nginx # 查看指定用户打开的文件 lsof -u www-data查看文件被哪些进程使用# 查看指定文件被哪些进程打开 lsof /var/log/nginx/access.log # 查看指定目录下的文件被哪些进程使用 lsof +D /var/log/文件系统相关找出被删除但未释放的文件 经常遇到这种情况:明明删除了大文件,但是df显示磁盘空间没有释放。这通常是因为文件被删除了,但还有进程在使用这个文件。# 查找被删除但未释放的文件 lsof | grep deleted # 或者更精确的查找 lsof +L1查看挂载点使用情况# 查看指定挂载点被哪些进程使用 lsof /mnt/data # 查看所有挂载点的使用情况 lsof -f -- /dev/sda1案例分享排查文件句柄泄漏 某个Python应用运行一段时间后就会报"Too many open files"的错误。怀疑是文件句柄泄漏。# 先找到进程PID ps aux | grep python_app # 查看进程打开的文件数量 lsof -p 12345 | wc -l # 查看具体打开了哪些文件 lsof -p 12345发现进程打开了大量的临时文件,而且数量一直在增长。最后定位到是代码里创建临时文件后没有正确清理。磁盘空间异常问题 服务器磁盘使用率突然飙升到95%,但是找不到大文件。后来用lsof发现有个日志轮转脚本有问题。排查发现有个进程打开了一个几GB的文件,但是这个文件在文件系统里找不到,原来是被删除了但进程还在写入。# 查找大文件 lsof | awk '$7 ~ /^[0-9]+$/ && $7 > 1000000 {print $2, $7, $9}' | sort -k2 -nr高级用法和技巧组合条件查询 lsof支持多种条件的组合,默认是OR关系,可以用-a参数改为AND关系。# 查看用户www-data打开的网络连接(OR关系) lsof -u www-data -i # 查看用户www-data打开的网络连接(AND关系) lsof -a -u www-data -i输出格式控制# 不显示主机名,直接显示IP lsof -n -i # 不显示端口名,直接显示端口号 lsof -P -i # 组合使用 lsof -nP -i:80这个在脚本里特别有用,因为解析主机名和端口名会比较慢。持续监控# 每2秒刷新一次 lsof -r 2 -i:80 # 监控到没有输出就退出 lsof +r 1 -i:80这个功能在调试网络连接问题的时候很有用,可以实时看到连接的变化。性能优化lsof虽然强大,但是在大型系统上运行可能会比较慢,特别是不加任何参数的时候。有几个优化技巧:尽量使用具体的参数,避免全量扫描使用-n和-P参数避免DNS和端口名解析在脚本中使用时,考虑缓存结果# 这样比较快 lsof -nP -i:80 # 这样会很慢 lsof | grep :80常见问题和注意事项使用lsof的时候有几个坑需要注意:权限问题:有些信息需要root权限才能看到系统负载:在高负载系统上运行lsof可能会影响性能输出解读:要理解各个字段的含义,特别是FD字段FD字段的含义比较复杂:cwd:当前工作目录txt:程序代码mem:内存映射文件数字:文件描述符号r、w、u:读、写、读写模式lsof的输出信息比较敏感,包含了很多系统内部的信息。在分享排查过程或者截图的时候,记得做好脱敏处理,避免泄露重要的系统信息。 -
TB级大文件处理脚本 #!/bin/bash # 处理TB级别日志文件的技巧 process_huge_file() { local file=$1 local chunk_size=${2:-1000000} # 默认100万行一个块 echo "处理大文件: $file ($(du -h "$file" | awk '{print $1}'))" # 方法1: 分块处理 split -l "$chunk_size" "$file" "chunk_" for chunk in chunk_*; do echo "处理块: $chunk" # 并行处理每个块 { awk '{ # 你的处理逻辑 ip_count[$1]++ } END { for (ip in ip_count) { print ip, ip_count[ip] > "result_'$chunk'.txt" } }' "$chunk" rm "$chunk" # 处理完立即删除 } & # 控制并发数 (($(jobs -r | wc -l) >= 4)) && wait done wait # 等待所有后台任务完成 # 合并结果 echo "合并结果..." awk '{sum[$1] += $2} END { for (ip in sum) print ip, sum[ip] }' result_chunk_*.txt | sort -k2 -nr > final_result.txt rm result_chunk_*.txt } # 方法2: 流式处理 (内存占用最小) stream_process() { local file=$1 # 使用管道流式处理,内存占用恒定 cat "$file" | \ awk '{ # 每处理10万行输出一次中间结果 if (NR % 100000 == 0) { print "处理进度:", NR > "/dev/stderr" } # 你的处理逻辑 ip_count[$1]++ # 定期清理内存 (保留热点数据) if (NR % 1000000 == 0) { for (ip in ip_count) { if (ip_count[ip] < 10) delete ip_count[ip] } } } END { for (ip in ip_count) { print ip, ip_count[ip] } }' | sort -k2 -nr }
-
数据库连接问题排查脚本 #!/bin/bash # 数据库连接问题排查脚本 echo "=== 数据库连接分析 ===" # 分析应用日志中的数据库错误 echo "数据库连接错误统计:" grep -i "database\|mysql\|connection" /var/log/myapp/error.log | \ grep -E "(timeout|refused|failed|error)" | \ sed 's/.*\[\([0-9-]*\).*/\1/' | \ sort | uniq -c | \ awk '{printf "%s: %d次错误\n", $2, $1}' # 分析慢查询日志 echo "慢查询TOP 10:" if [ -f /var/log/mysql/slow.log ]; then grep "Query_time" /var/log/mysql/slow.log | \ awk '{print $3}' | \ sort -nr | head -10 | \ awk '{printf "查询时间: %.2f秒\n", $1}' fi # 检查连接池状态 echo "当前数据库连接数:" mysql -e "SHOW STATUS LIKE 'Threads_connected';" 2>/dev/null | \ awk 'NR==2 {print "活跃连接:", $2}'
-
分布式处理脚本 #!/bin/bash # 分布式日志处理脚本 SERVERS=("server1" "server2" "server3") LOG_FILE="/var/log/nginx/access.log" distribute_process() { local total_lines=$(wc -l < "$LOG_FILE") local lines_per_server=$((total_lines / ${#SERVERS[@]})) echo "总行数: $total_lines, 每台服务器处理: $lines_per_server 行" for i in "${!SERVERS[@]}"; do local server="${SERVERS[$i]}" local start_line=$((i * lines_per_server + 1)) local end_line=$(((i + 1) * lines_per_server)) echo "分发给 $server: 行 $start_line - $end_line" # 提取对应行数并发送到远程服务器处理 sed -n "${start_line},${end_line}p" "$LOG_FILE" | \ ssh "$server" " awk '{ip_count[\$1]++} END { for (ip in ip_count) print ip, ip_count[ip] }' > /tmp/result_$i.txt " & done wait # 收集结果 echo "收集结果..." for i in "${!SERVERS[@]}"; do scp "${SERVERS[$i]}:/tmp/result_$i.txt" "result_$i.txt" done # 合并最终结果 awk '{sum[$1] += $2} END { for (ip in sum) print ip, sum[ip] }' result_*.txt | sort -k2 -nr > distributed_result.txt rm result_*.txt }
-
性能问题排查脚本 #!/bin/bash # 性能问题排查脚本 echo "=== 性能分析报告 ===" # 慢请求分析 (假设nginx记录了响应时间) echo "响应时间 > 2秒的请求:" awk '$NF > 2.0 {print $1, $7, $NF"s"}' /var/log/nginx/access.log | \ sort -k3 -nr | head -20 # 大文件传输分析 echo "传输量 > 10MB的请求:" awk '$10 > 10485760 {printf "%s %s %.2fMB\n", $1, $7, $10/1024/1024}' \ /var/log/nginx/access.log | sort -k3 -nr # 并发分析 echo "每分钟请求数统计:" awk '{print substr($4, 2, 16)}' /var/log/nginx/access.log | \ sort | uniq -c | \ awk '{print $2, $1}' | \ sort -k1